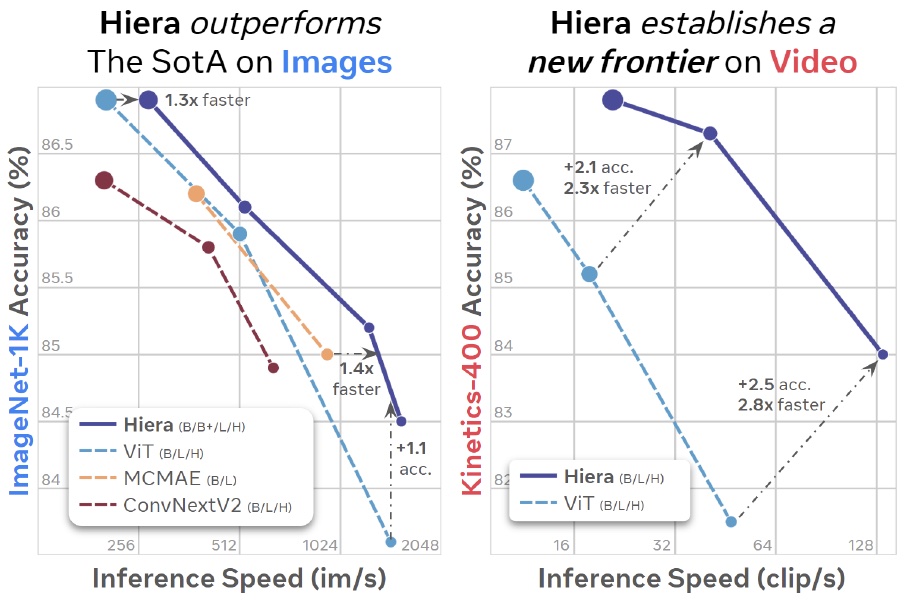
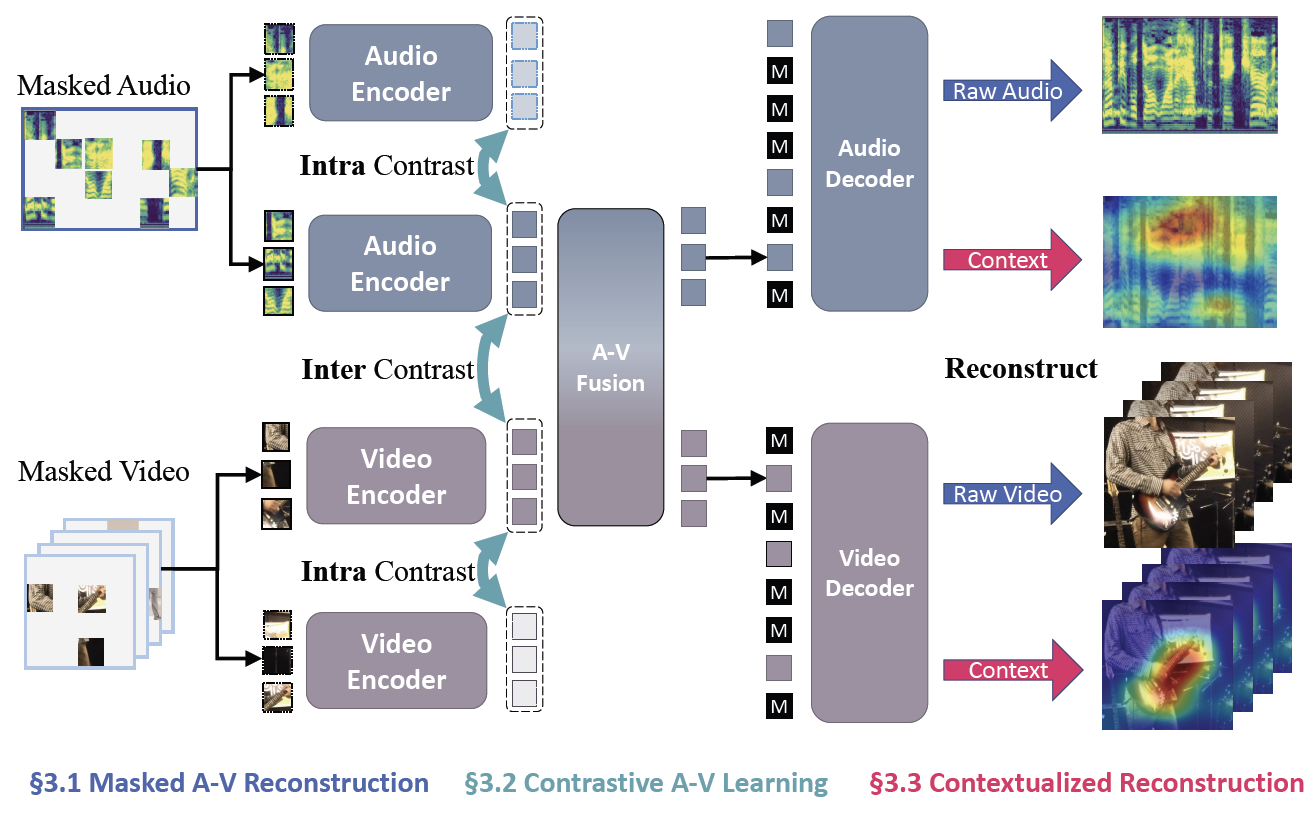
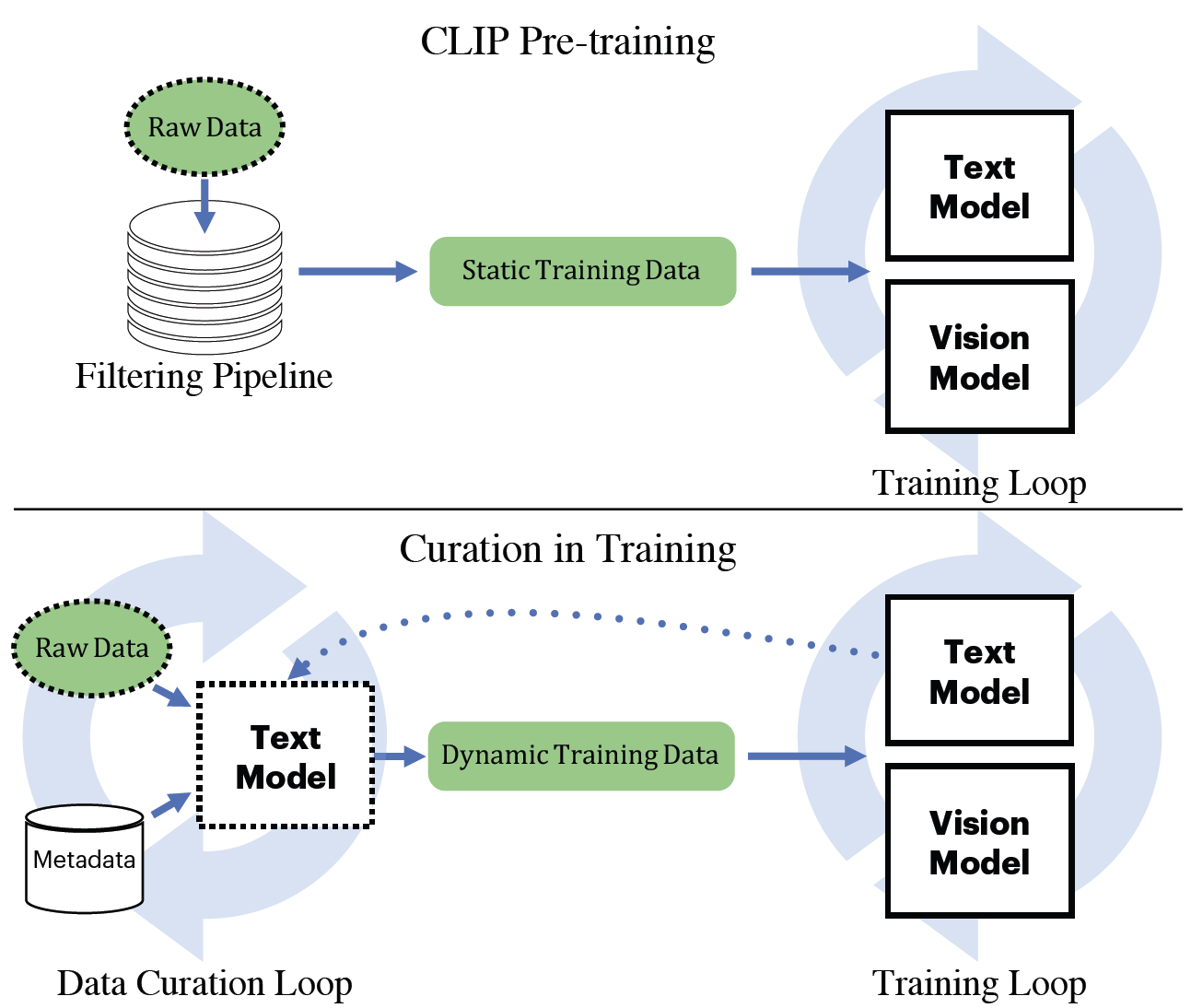
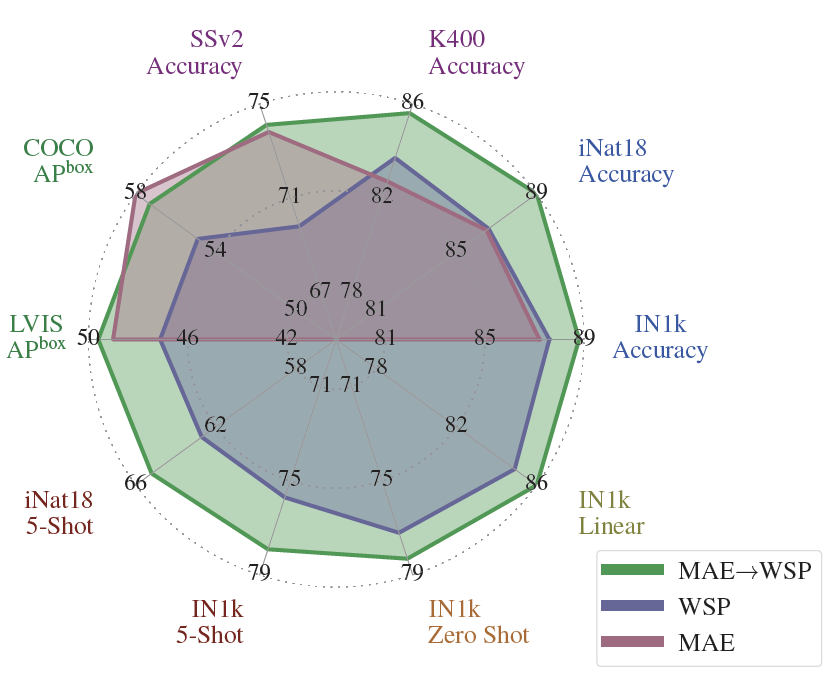
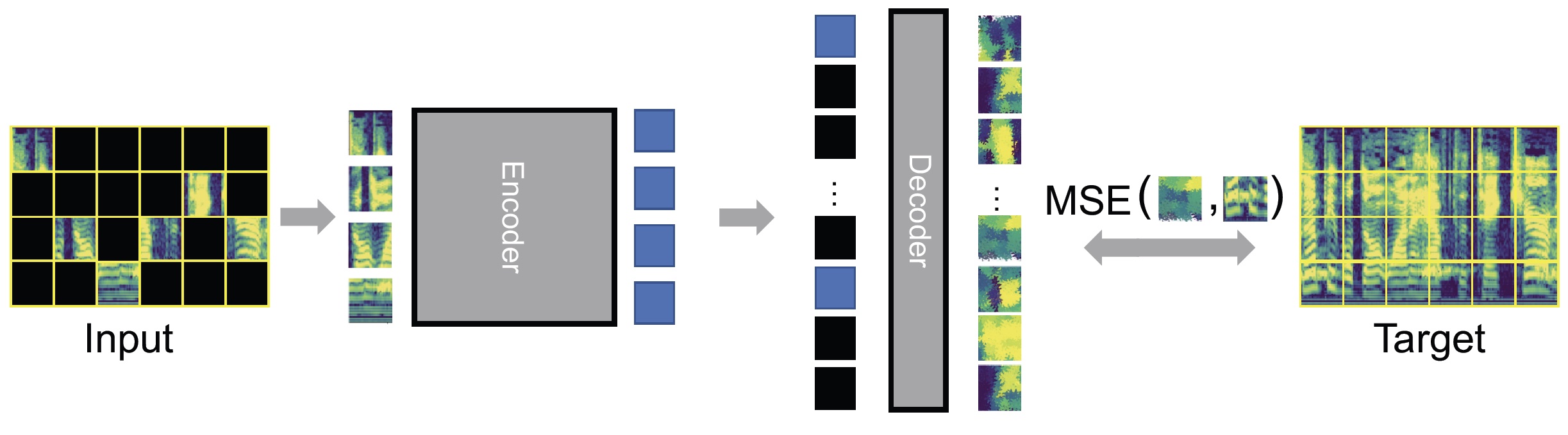
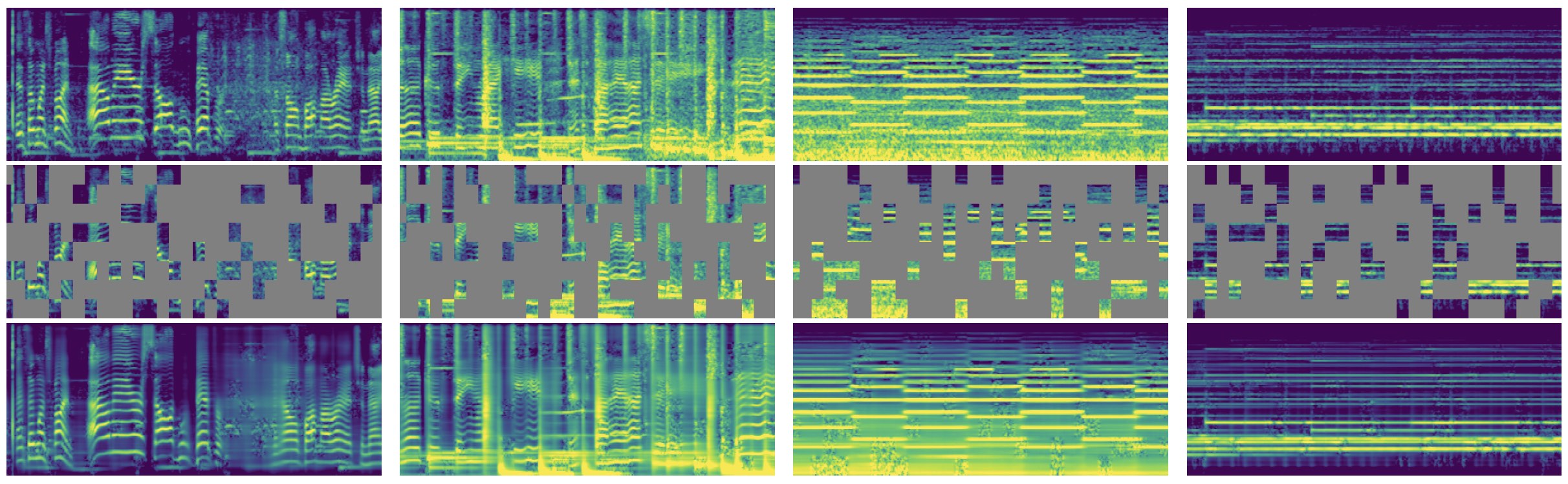
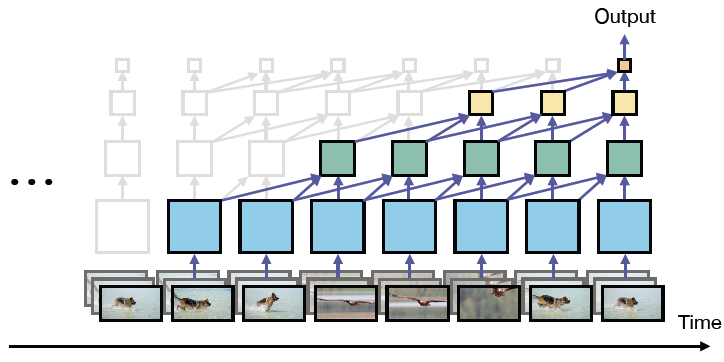
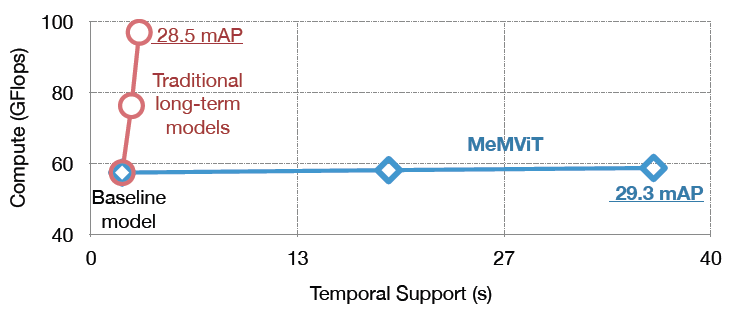
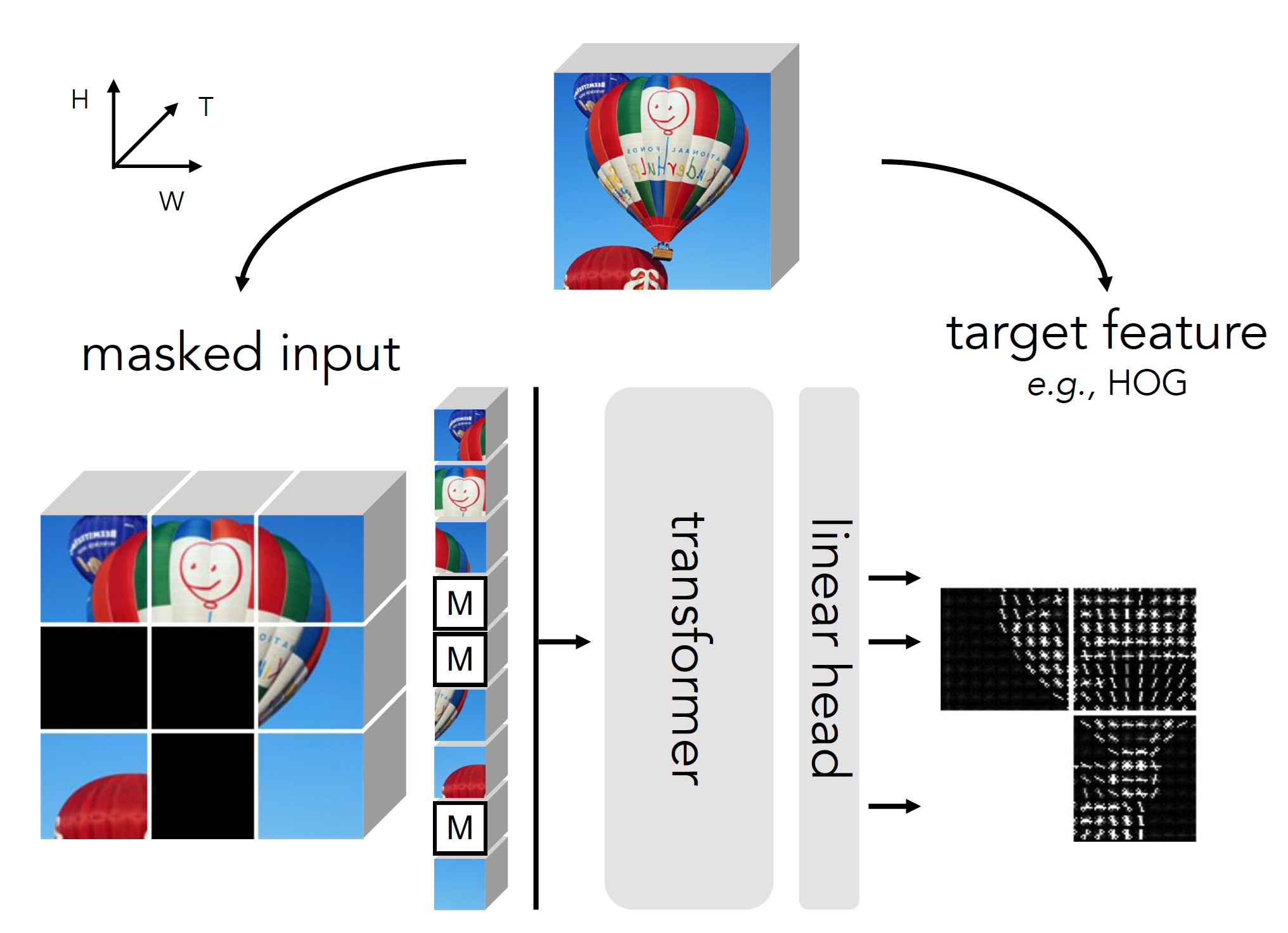
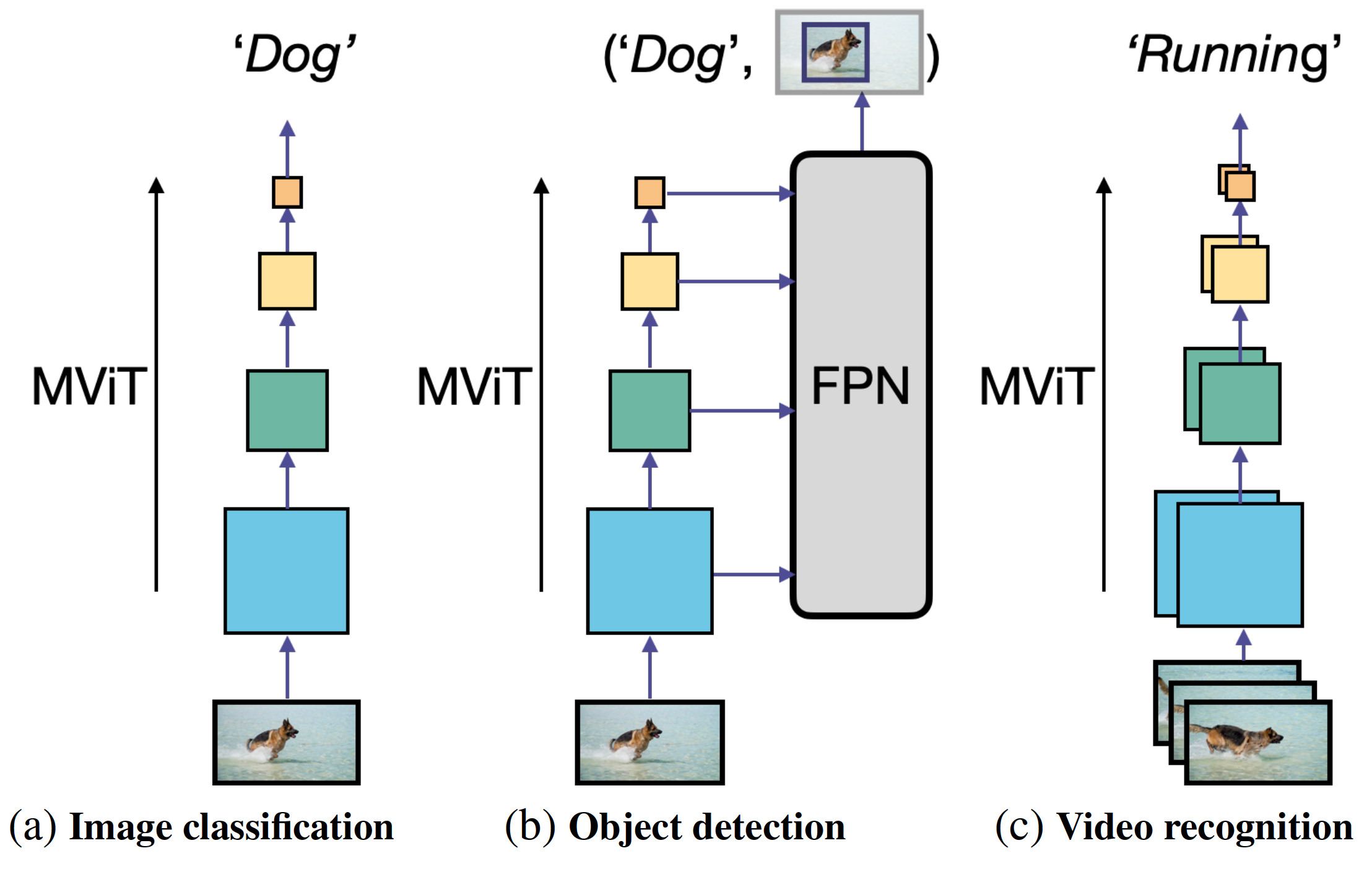
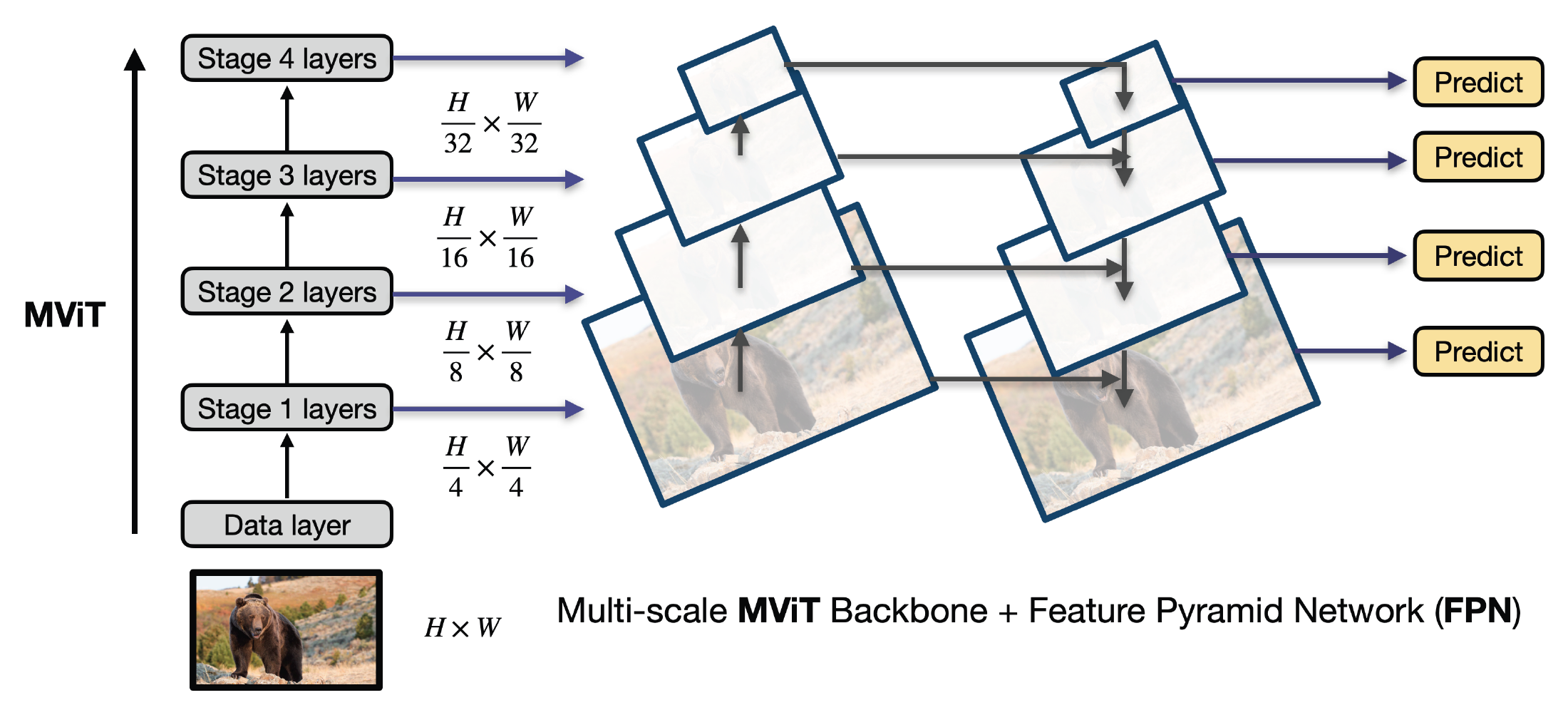
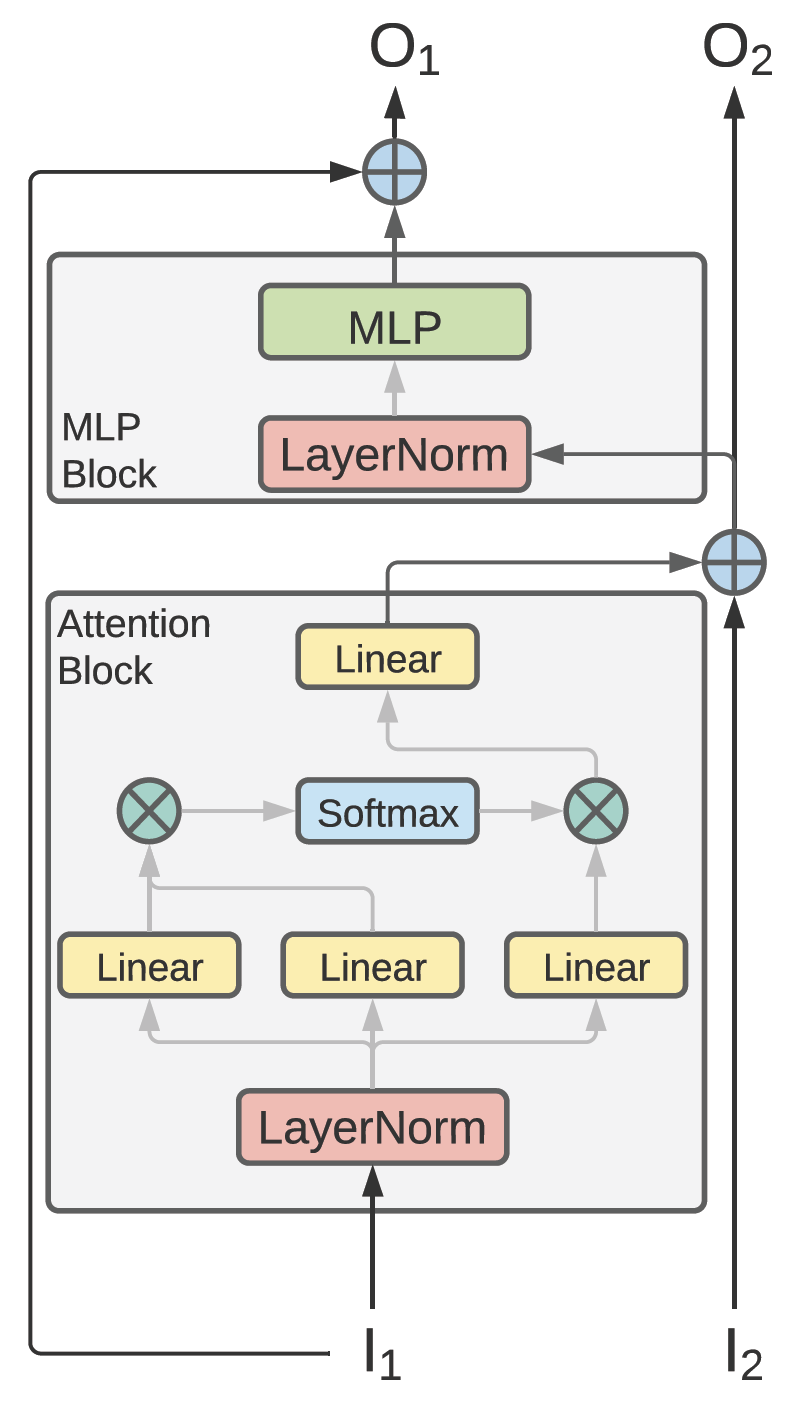
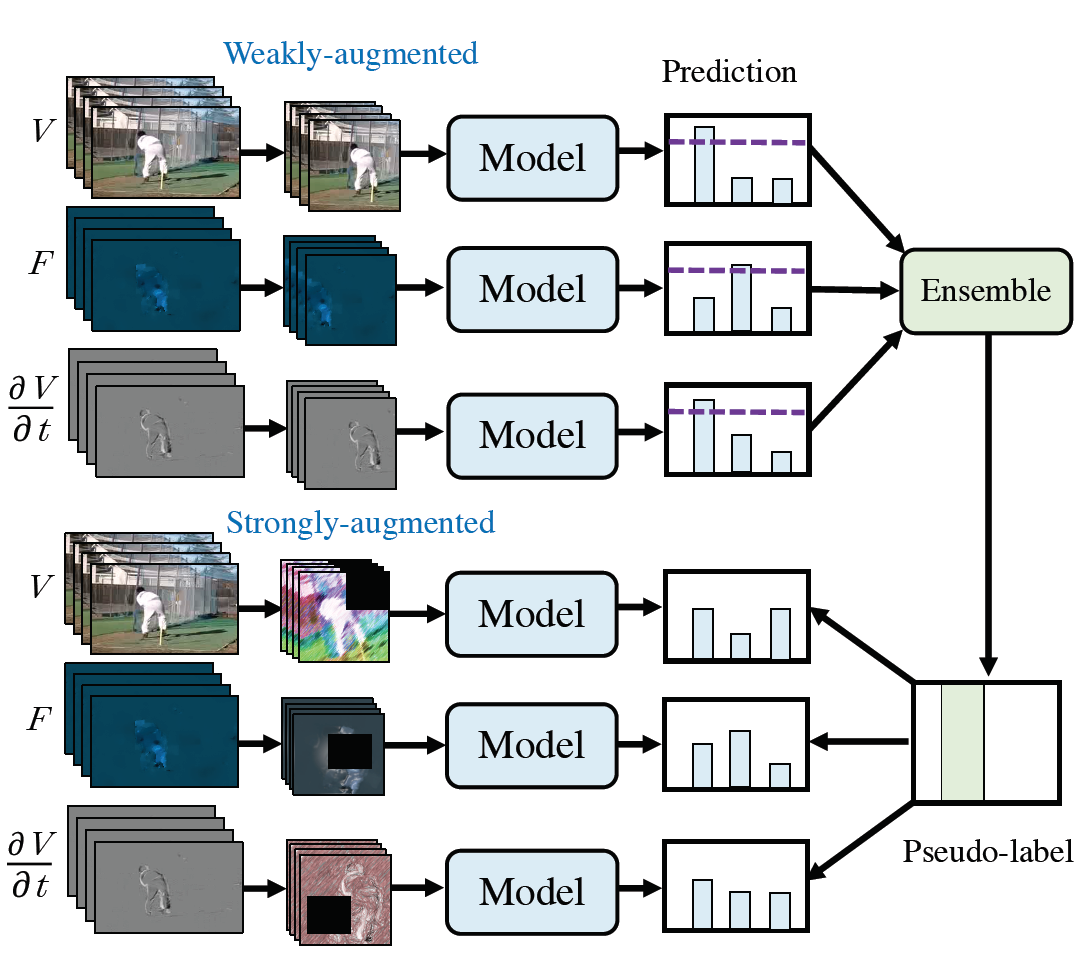
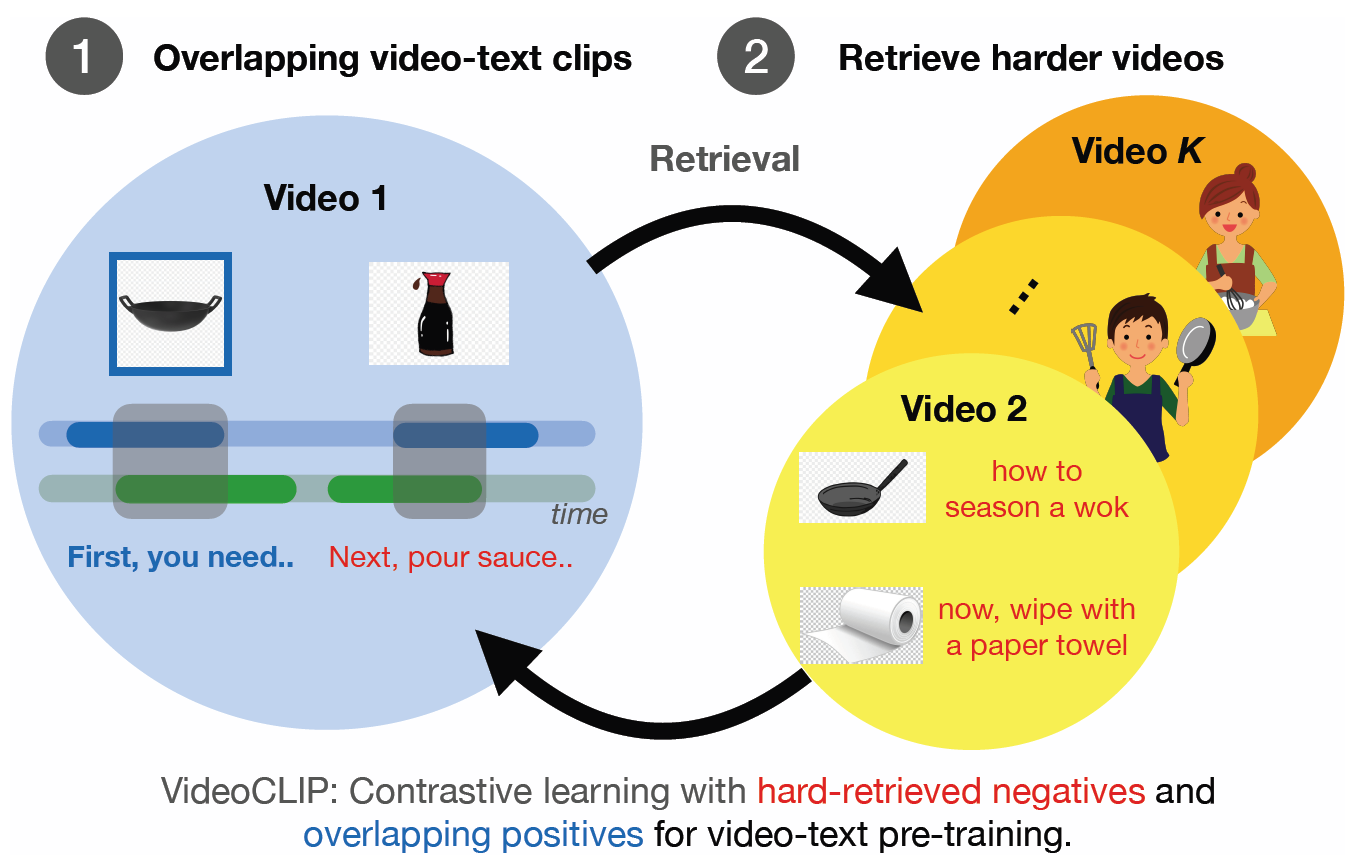
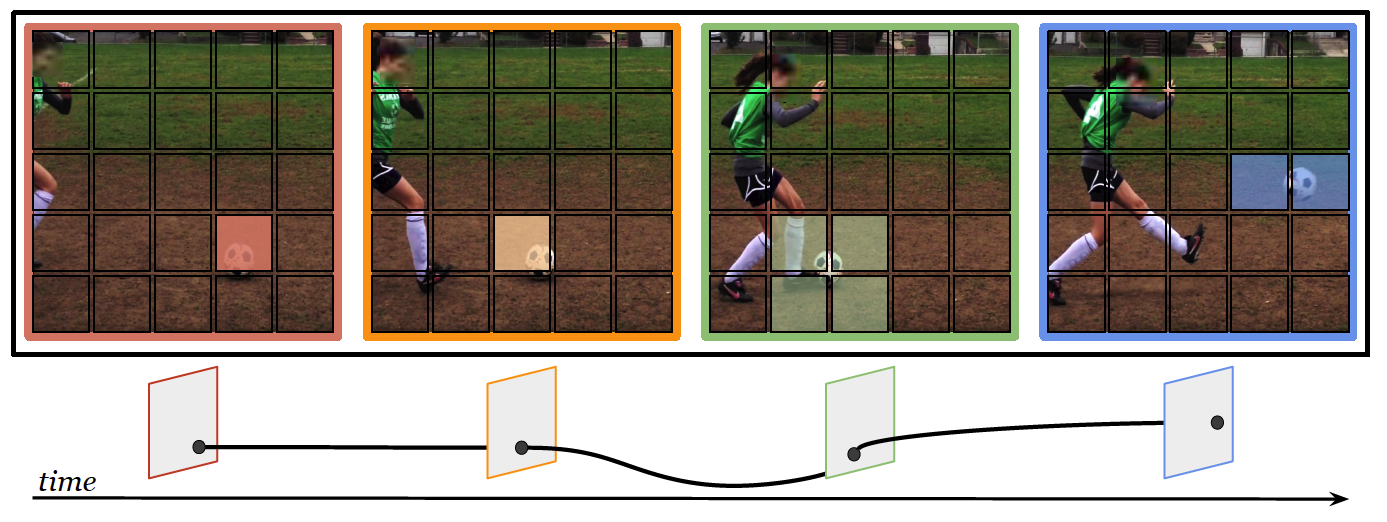
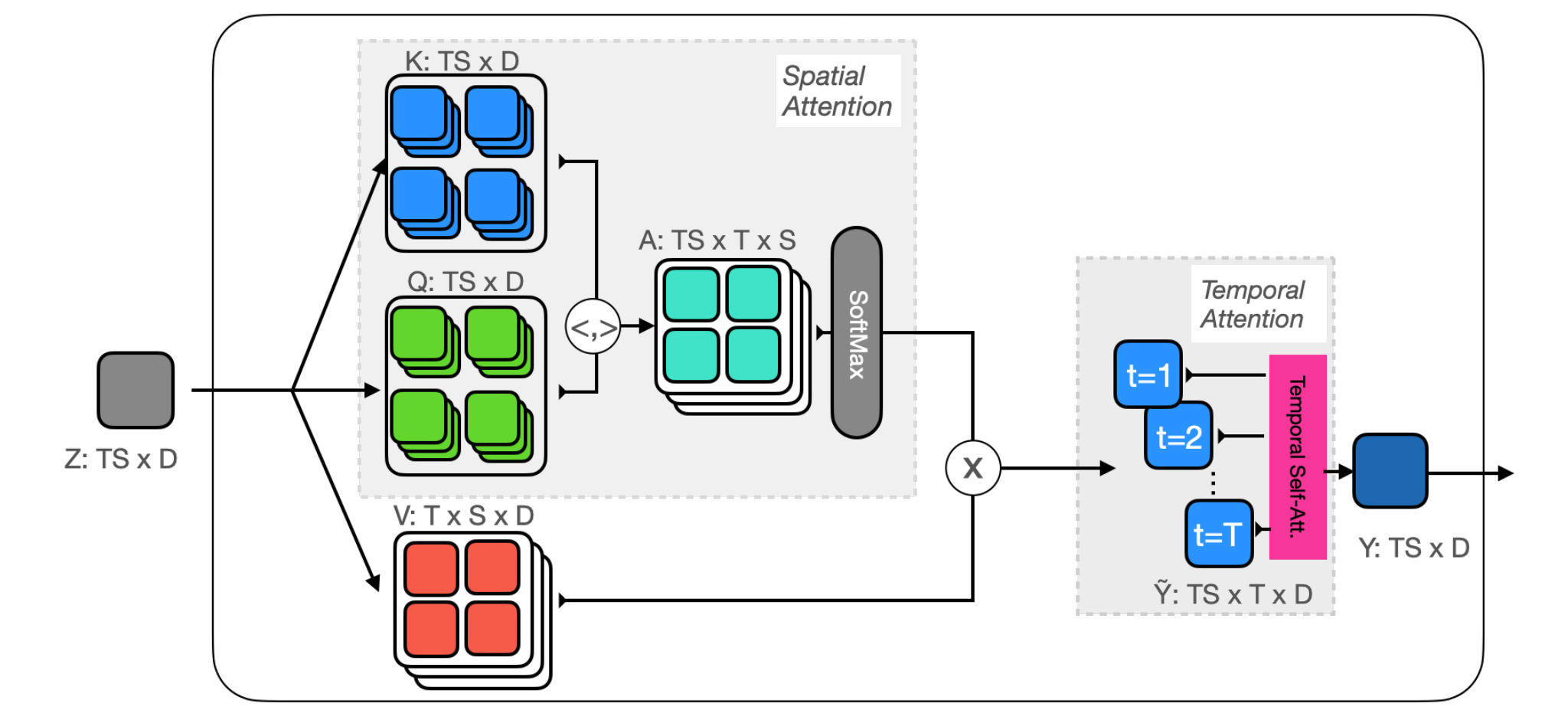
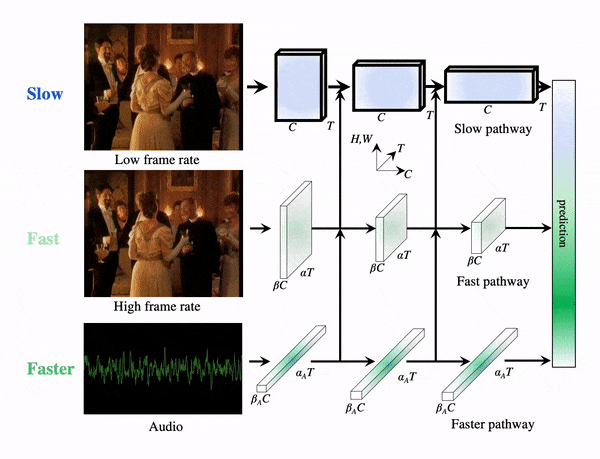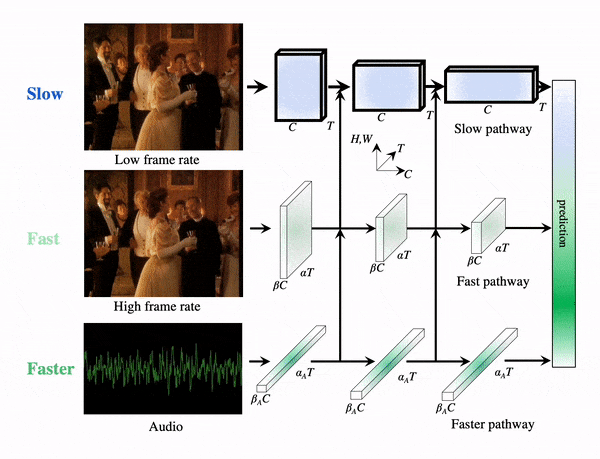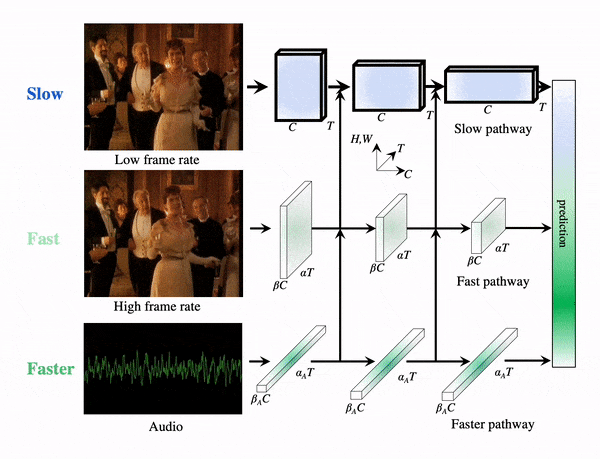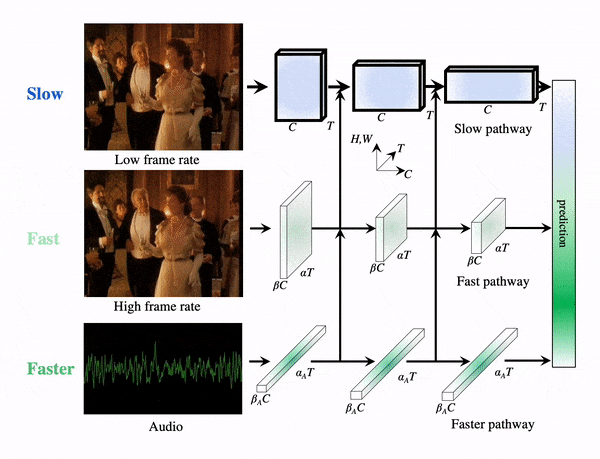
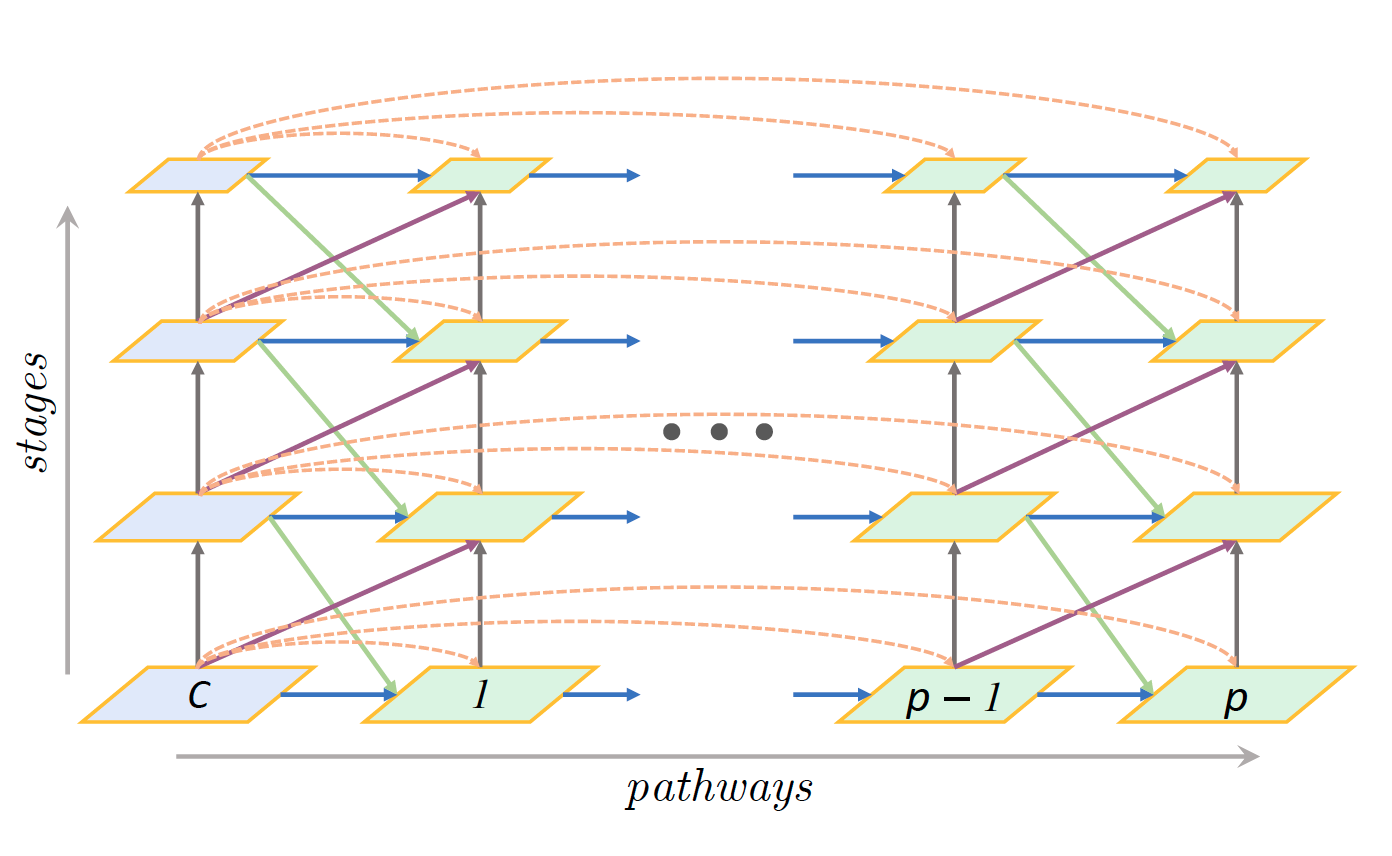
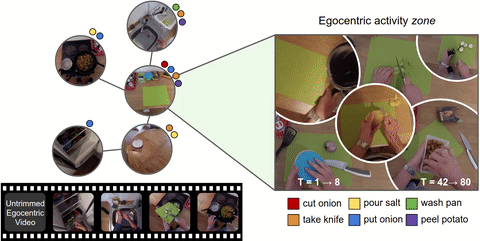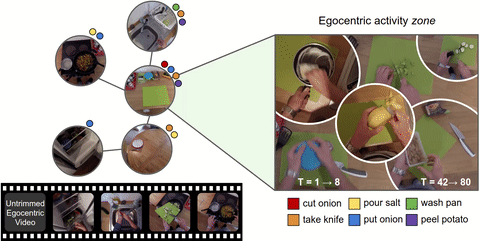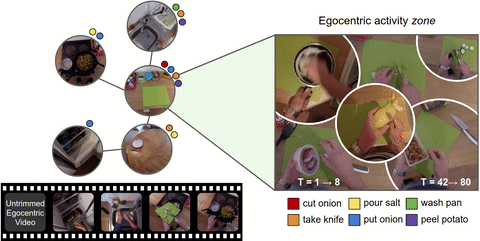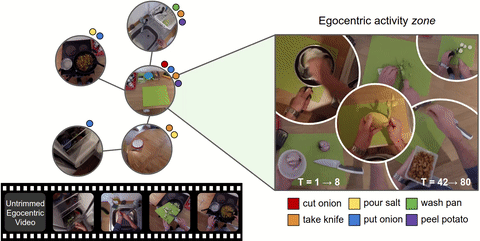
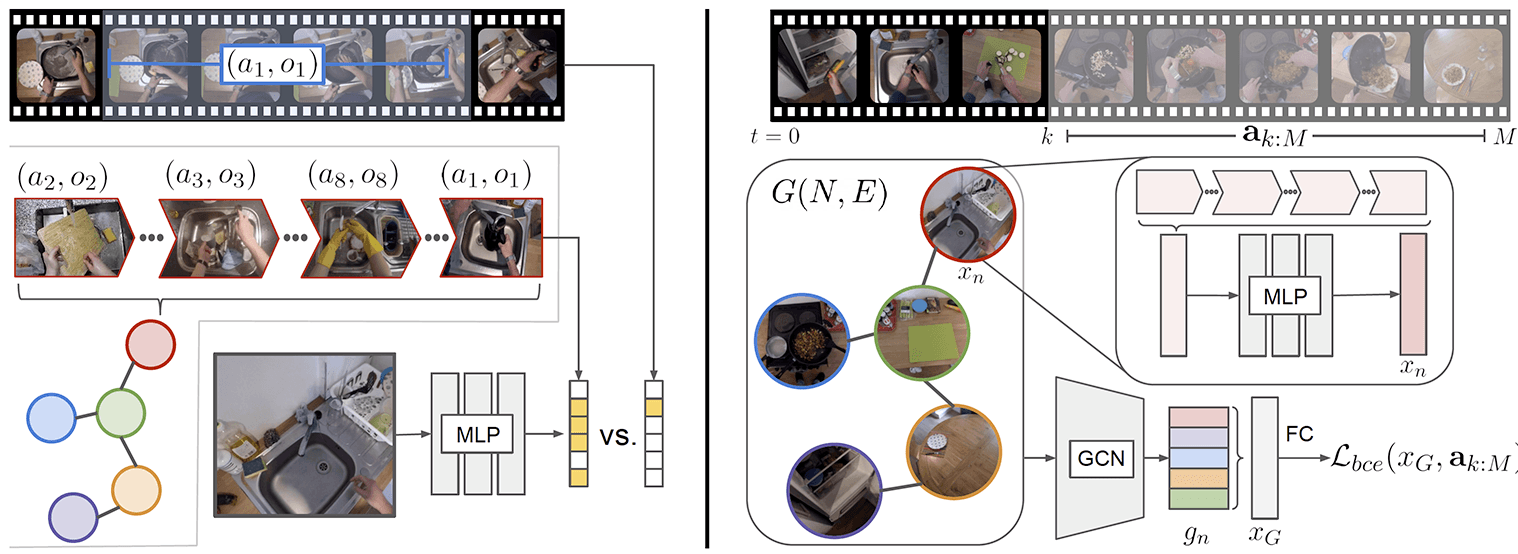
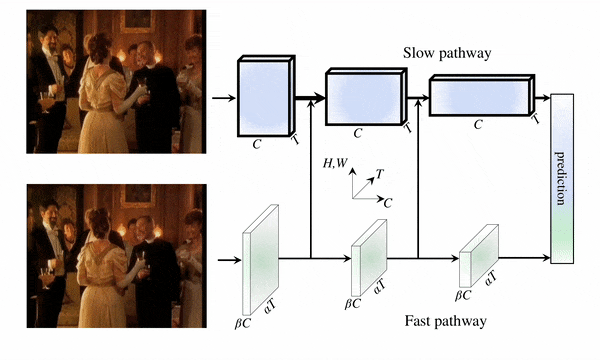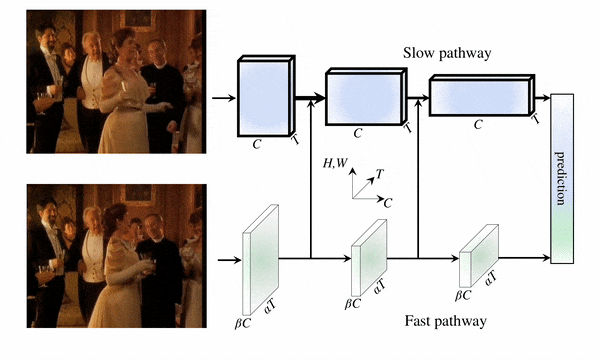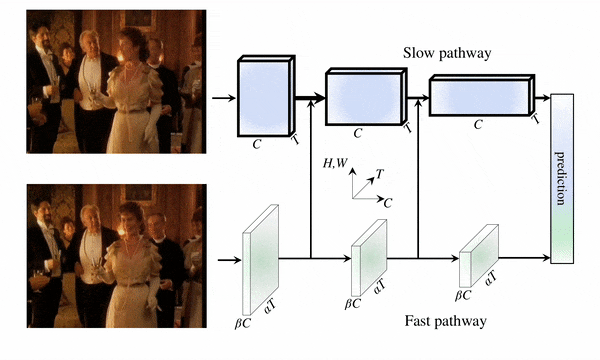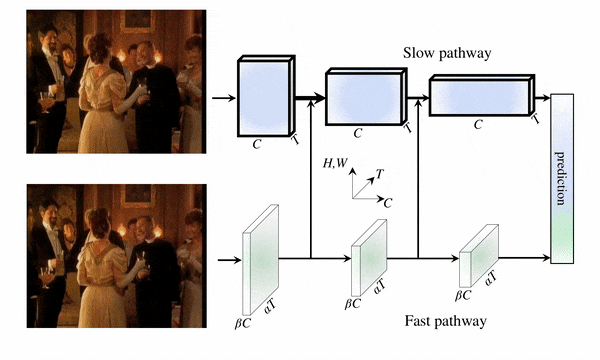
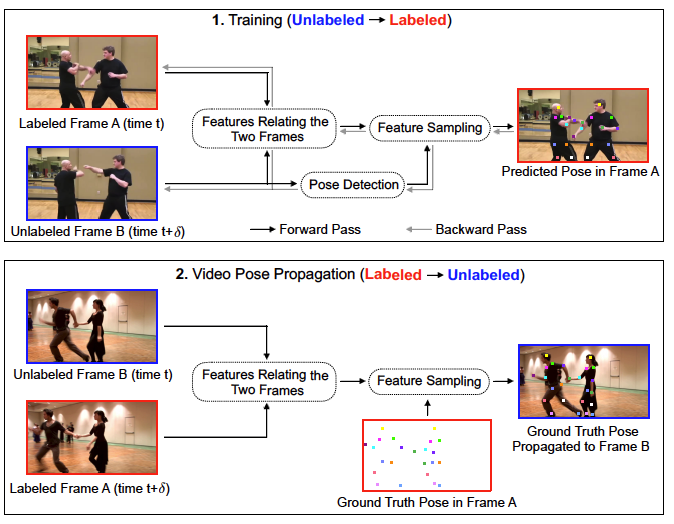
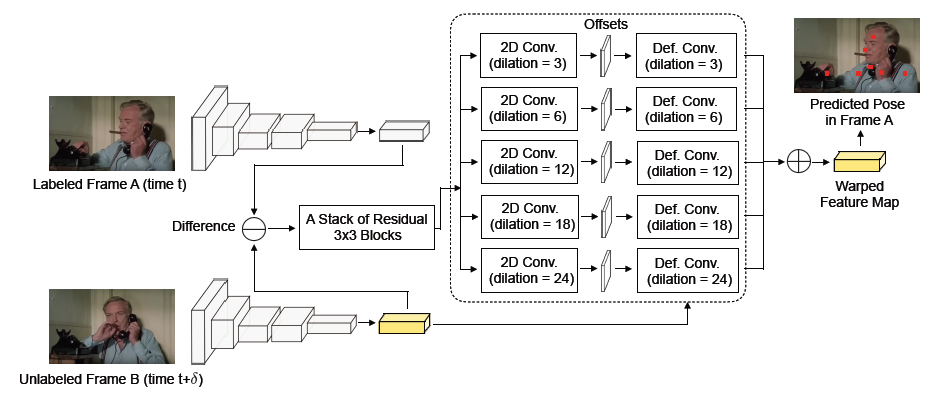
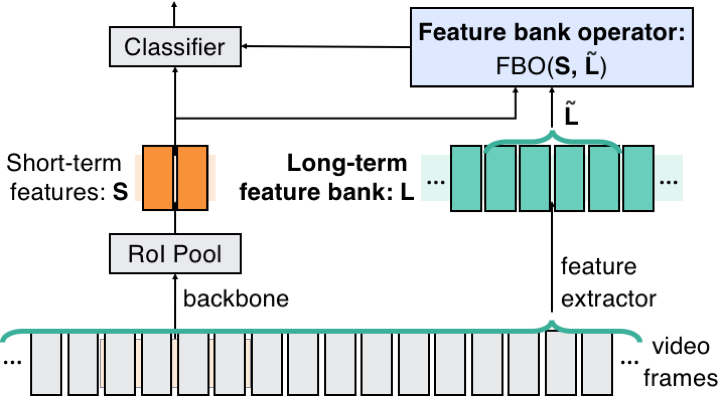
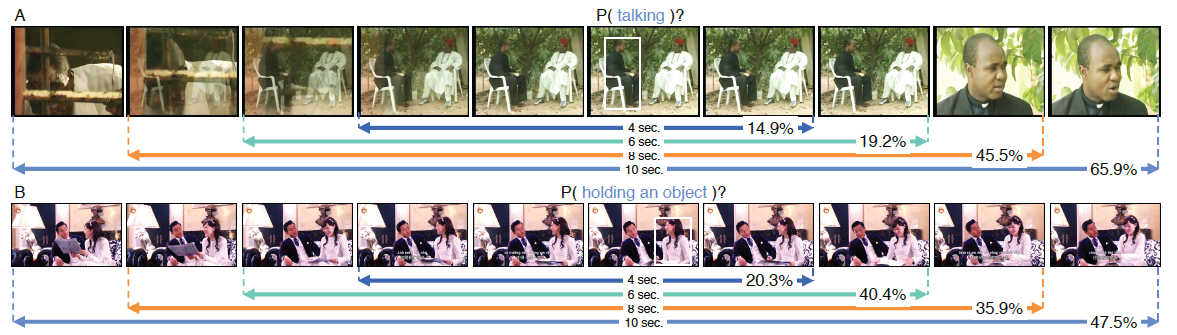
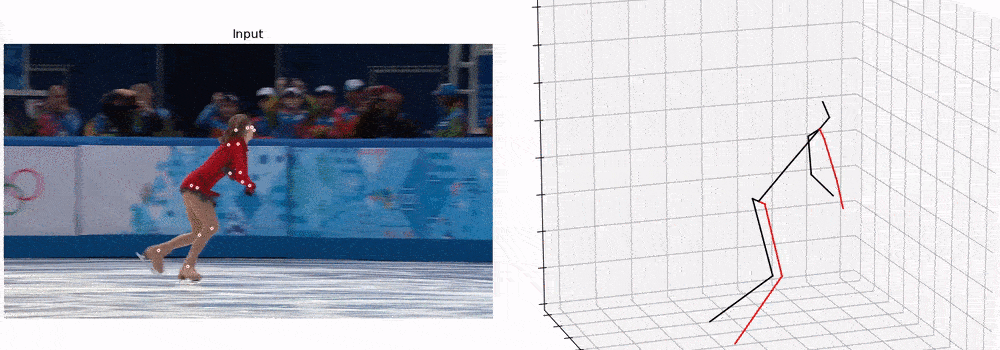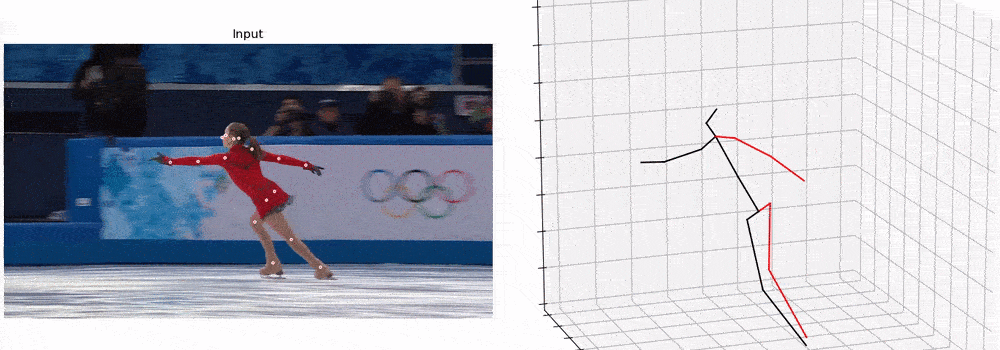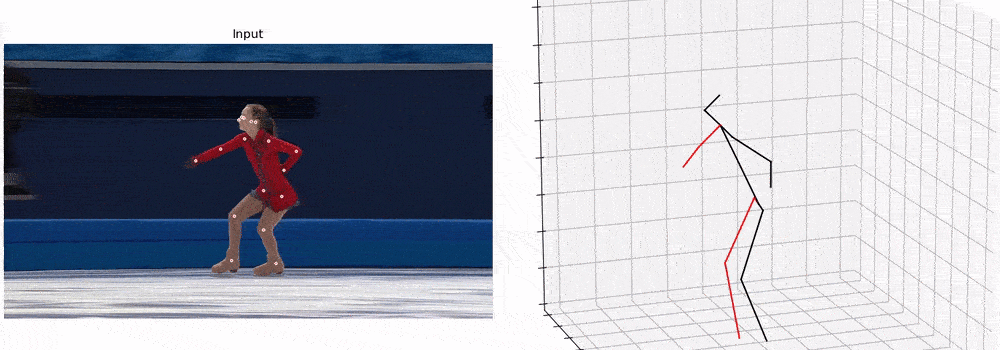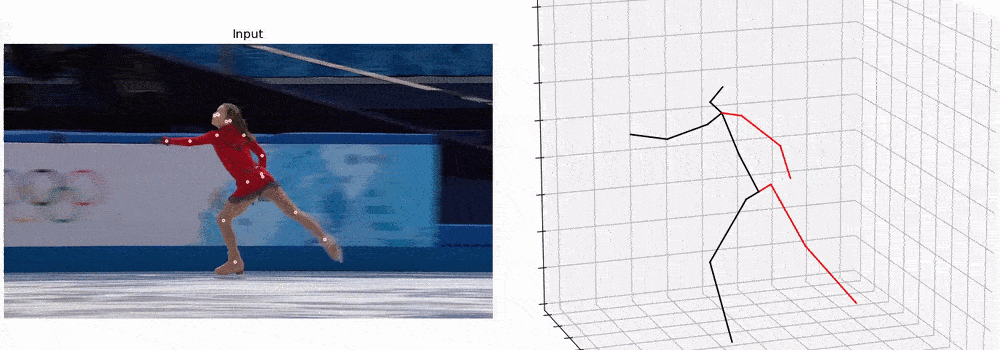PyTorchVideo: A Deep Learning Library for Video Understanding
Haoqi Fan, Tullie Murrell, Heng Wang, Kalyan Vasudev Alwala, Yanghao Li, Yilei Li, Bo Xiong,
Nikhila Ravi, Meng Li,
Haichuan Yang, Jitendra Malik, Ross Girshick, Matt Feiszli, Aaron Adcock, Wan-Yen Lo, Christoph
Feichtenhofer
Proceedings of the 29th ACM International Conference on Multimedia, 2021
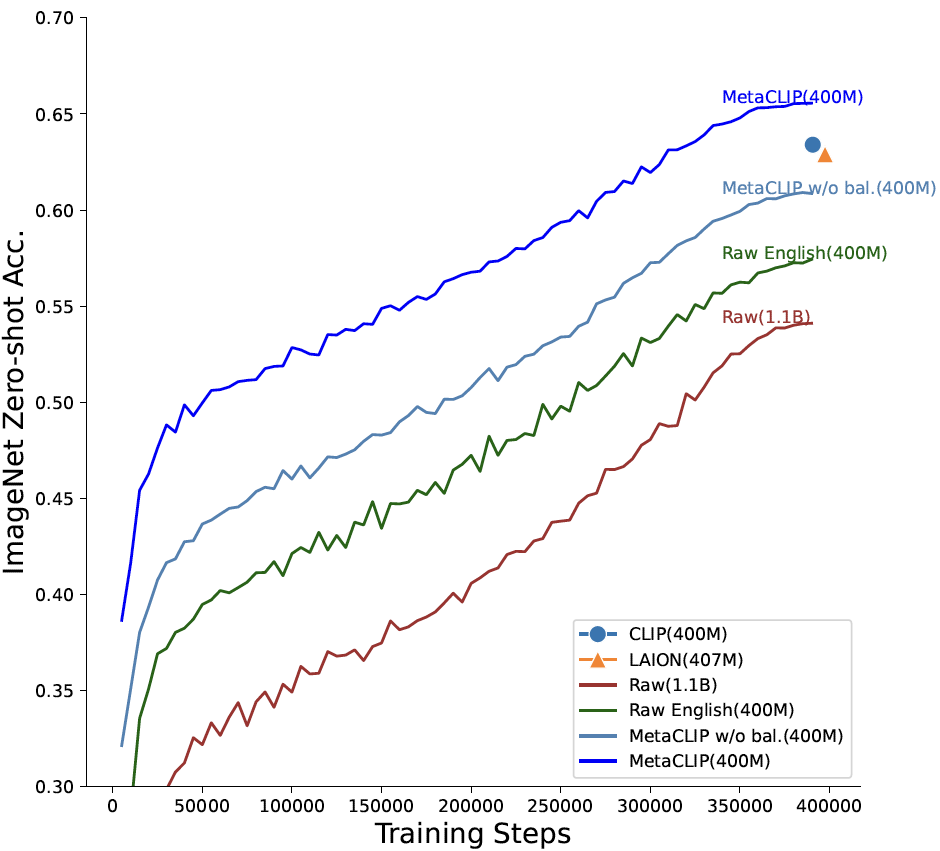
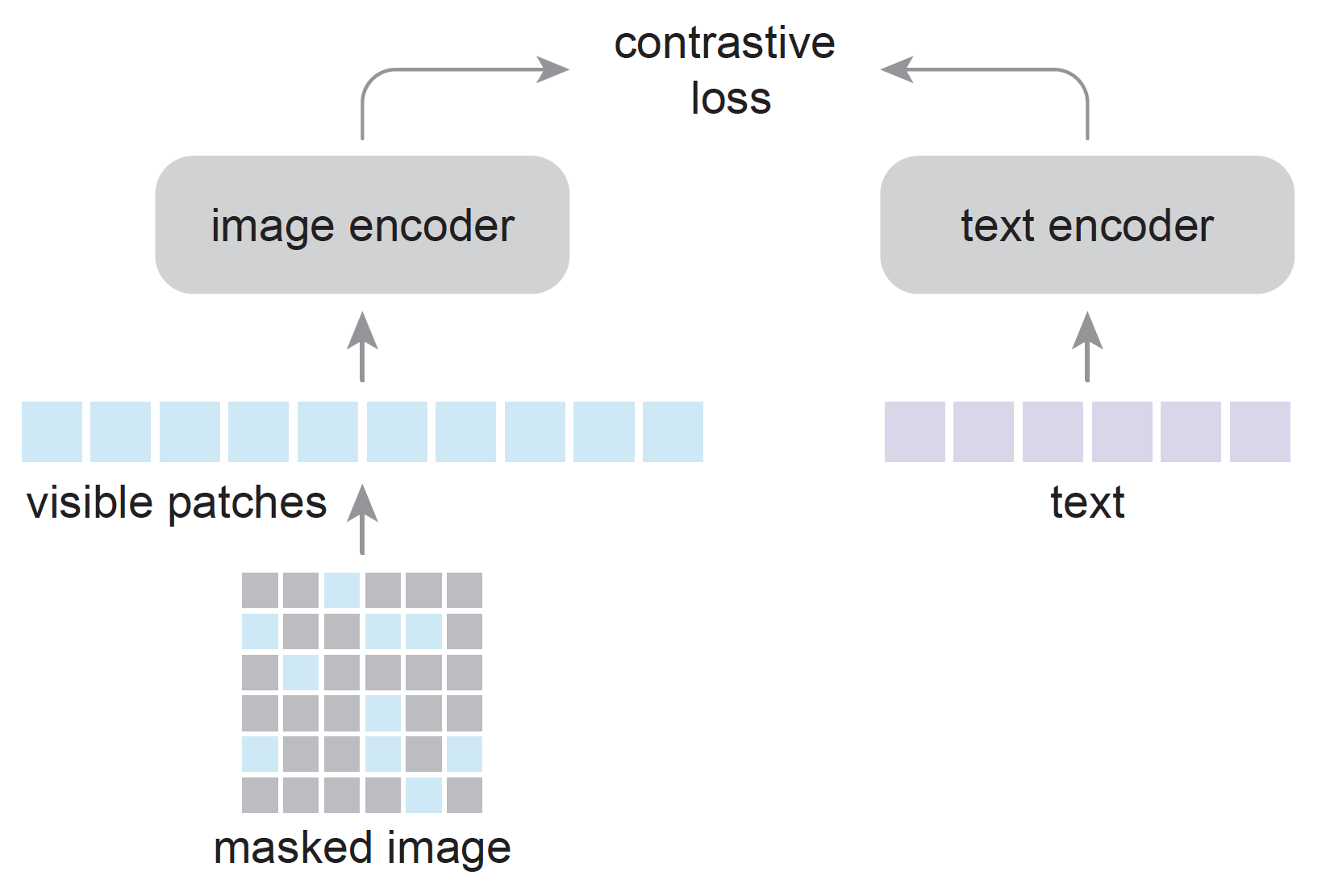
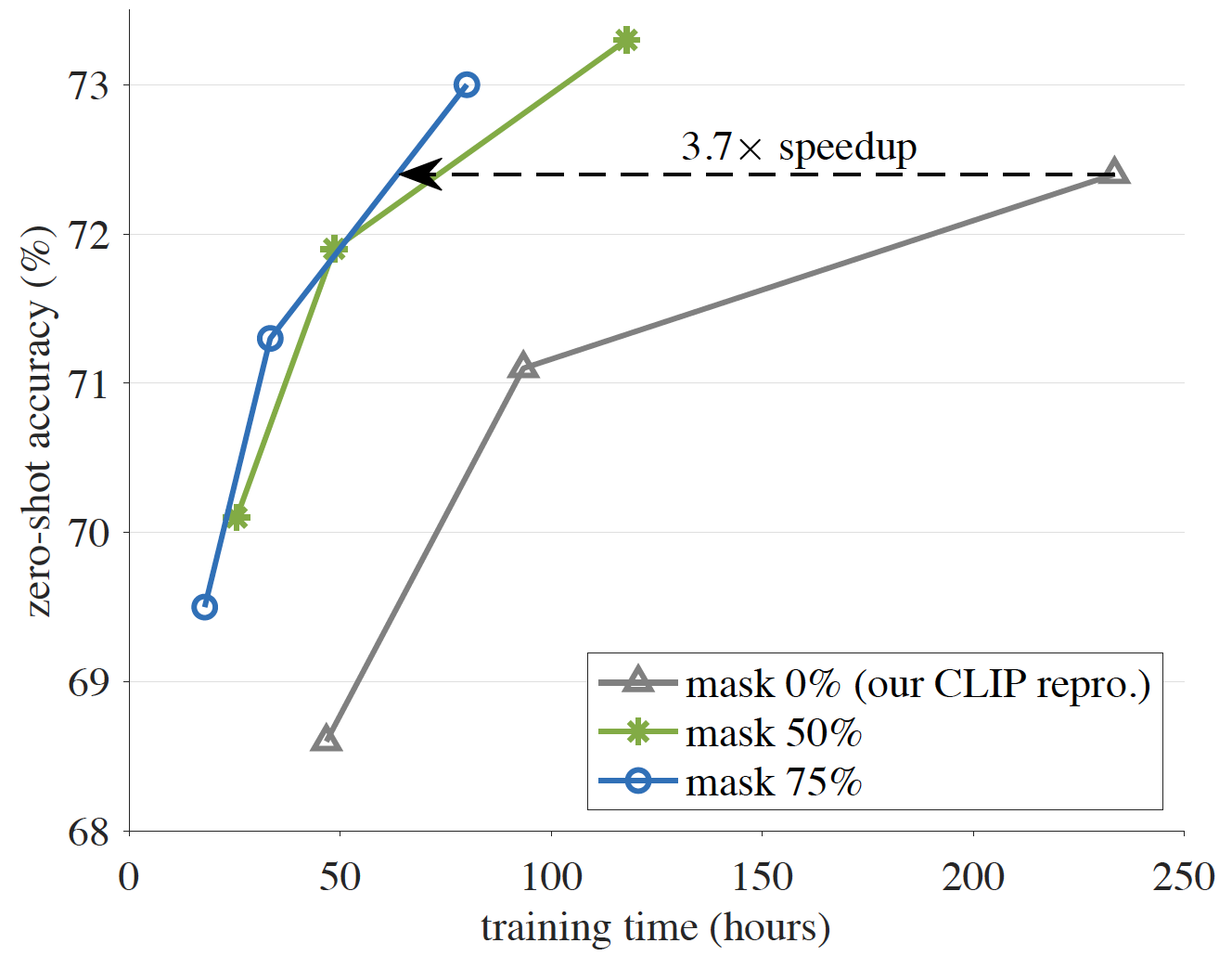
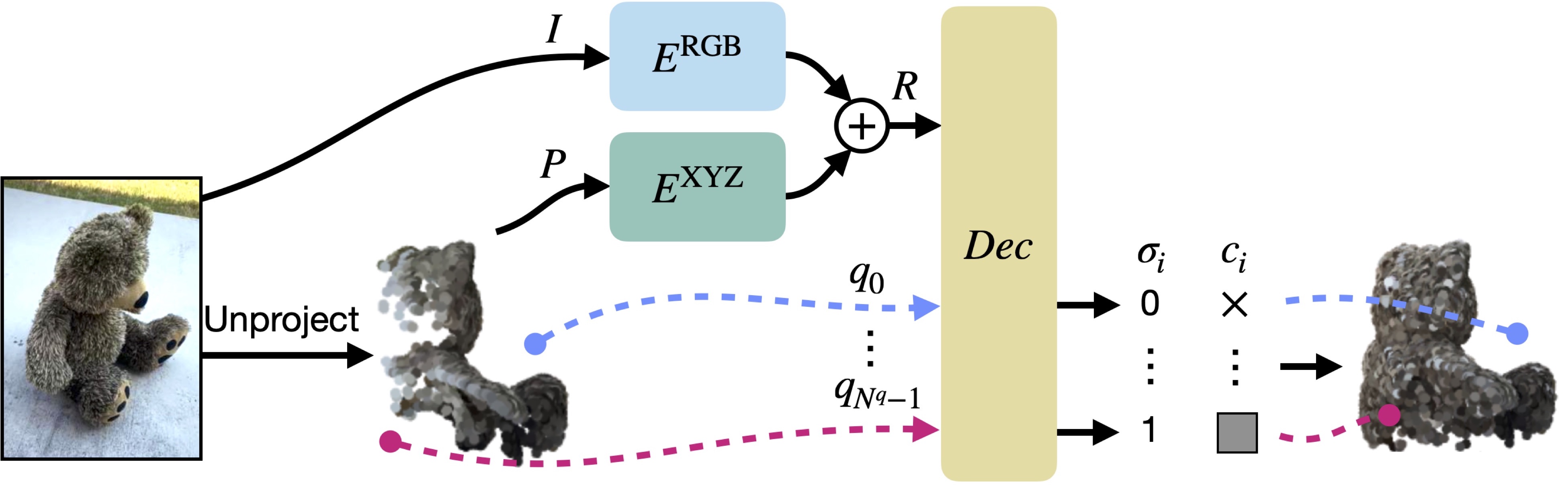
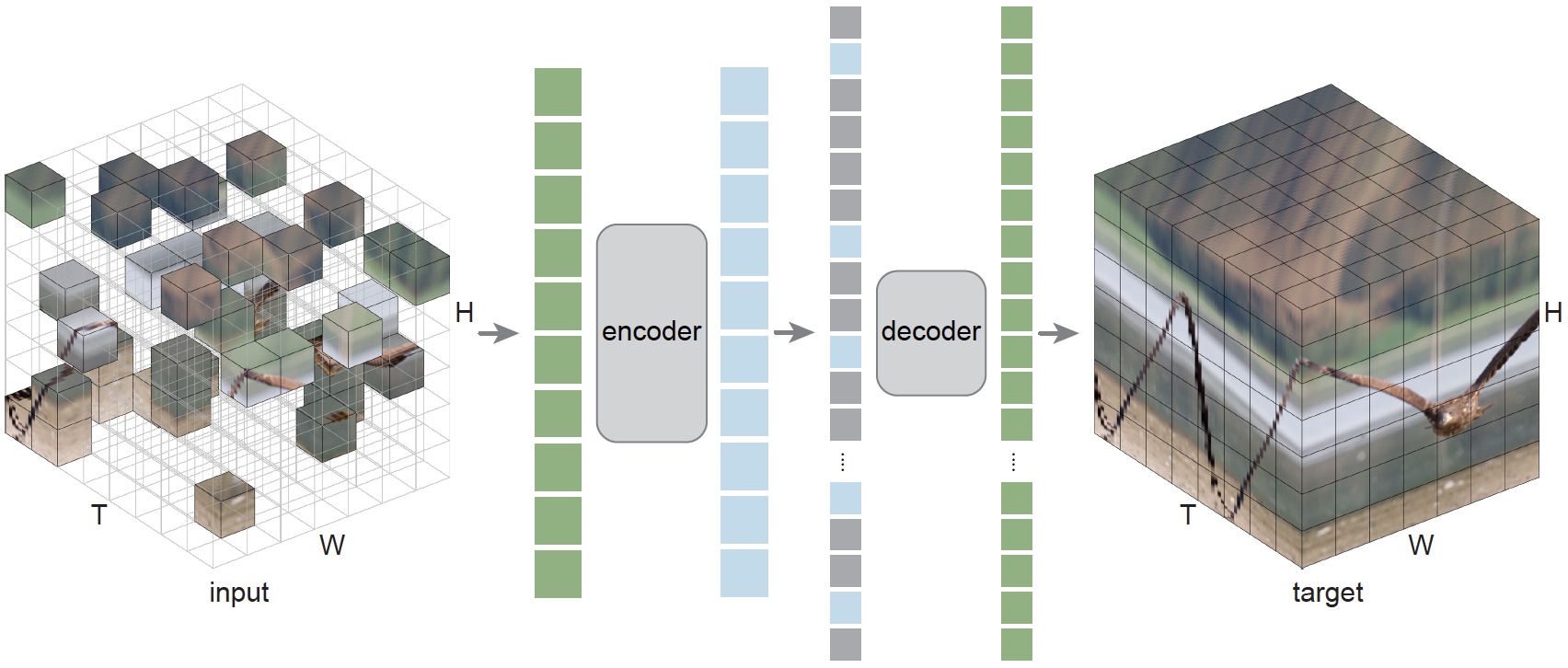
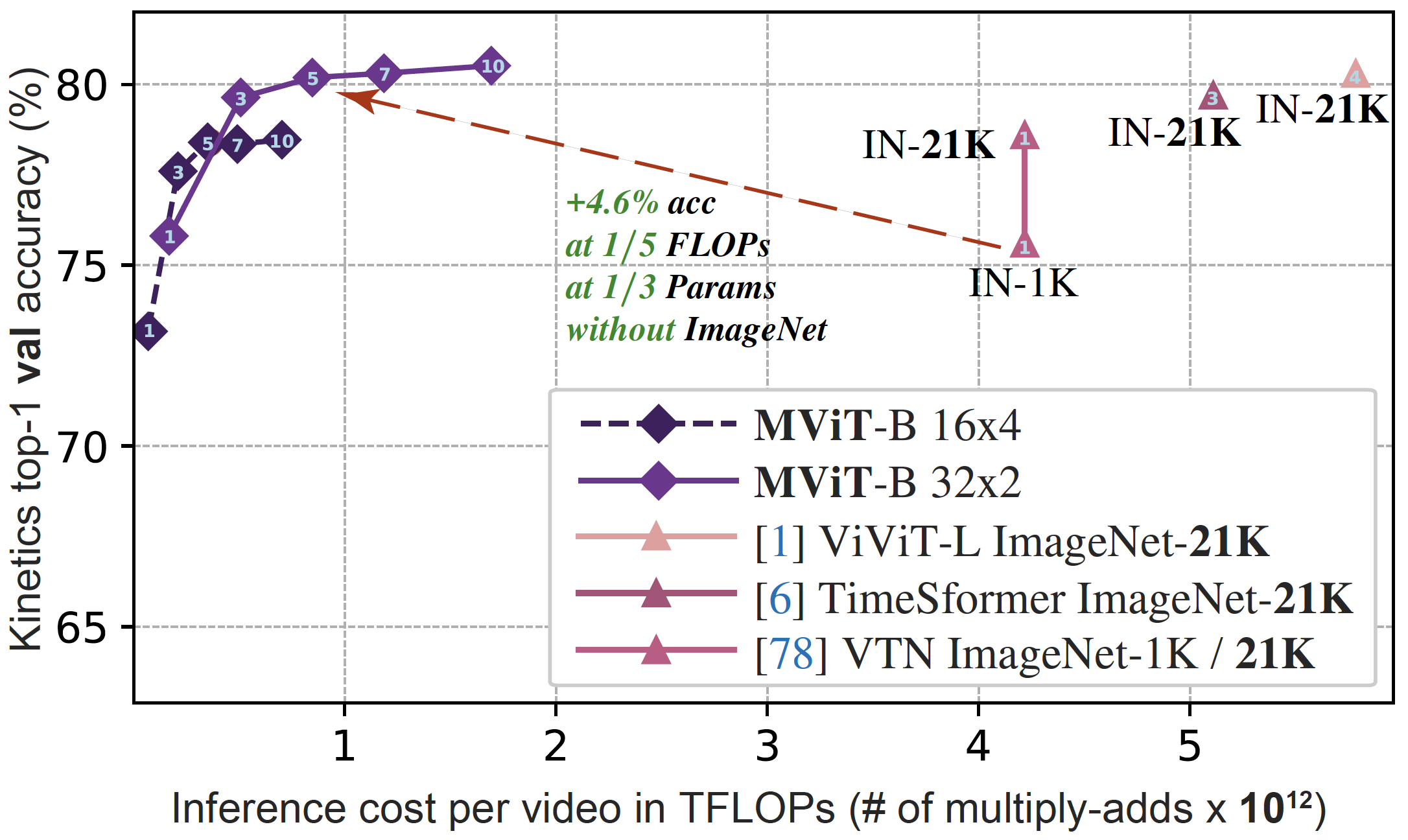
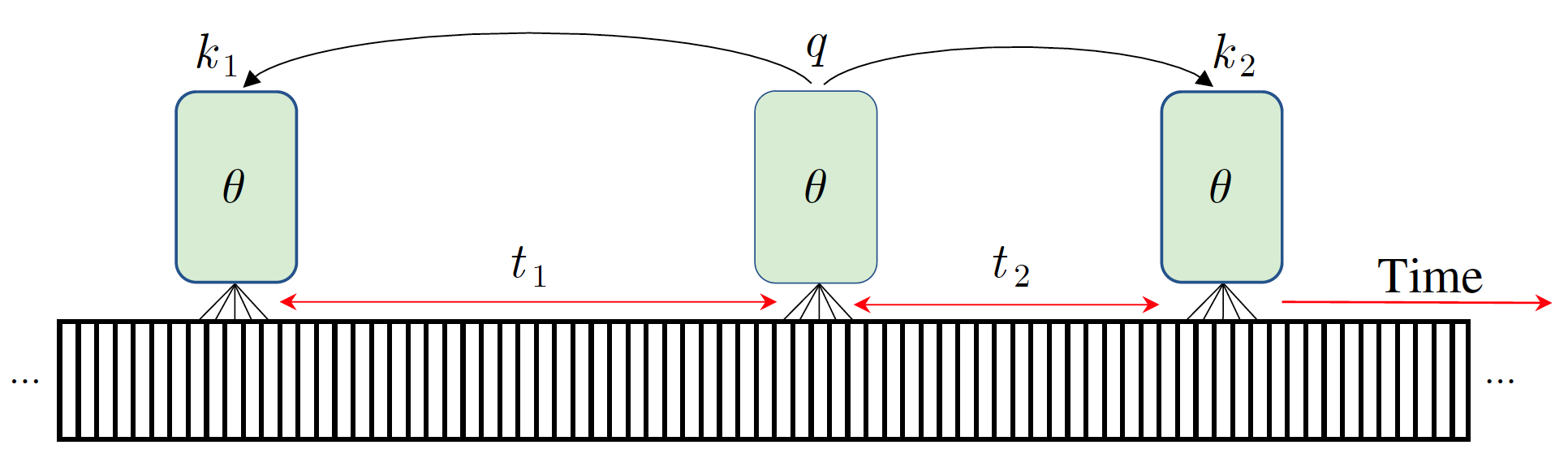
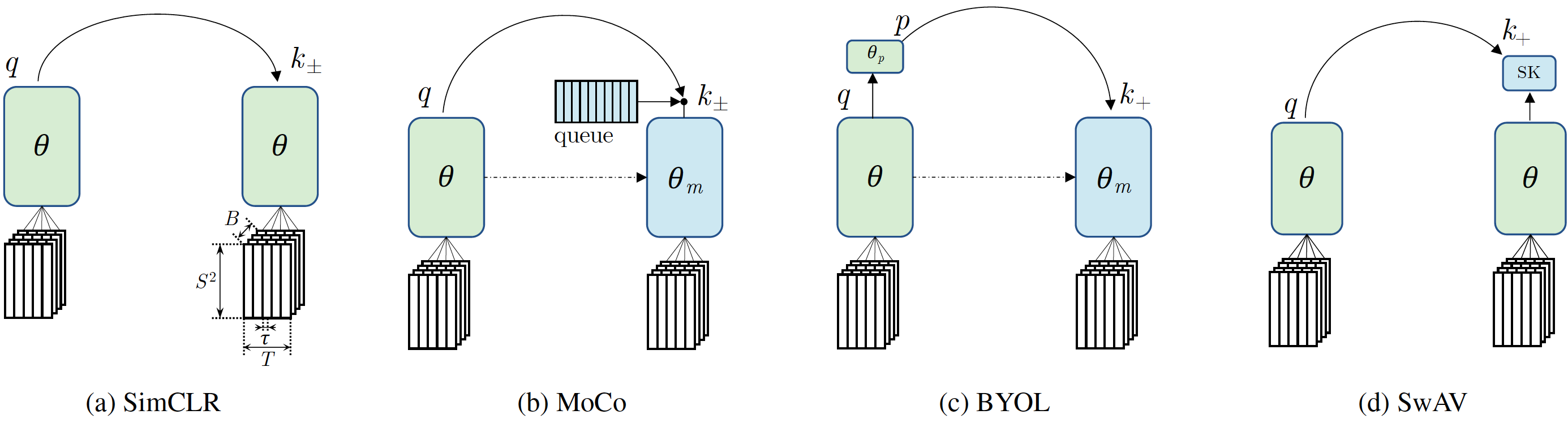
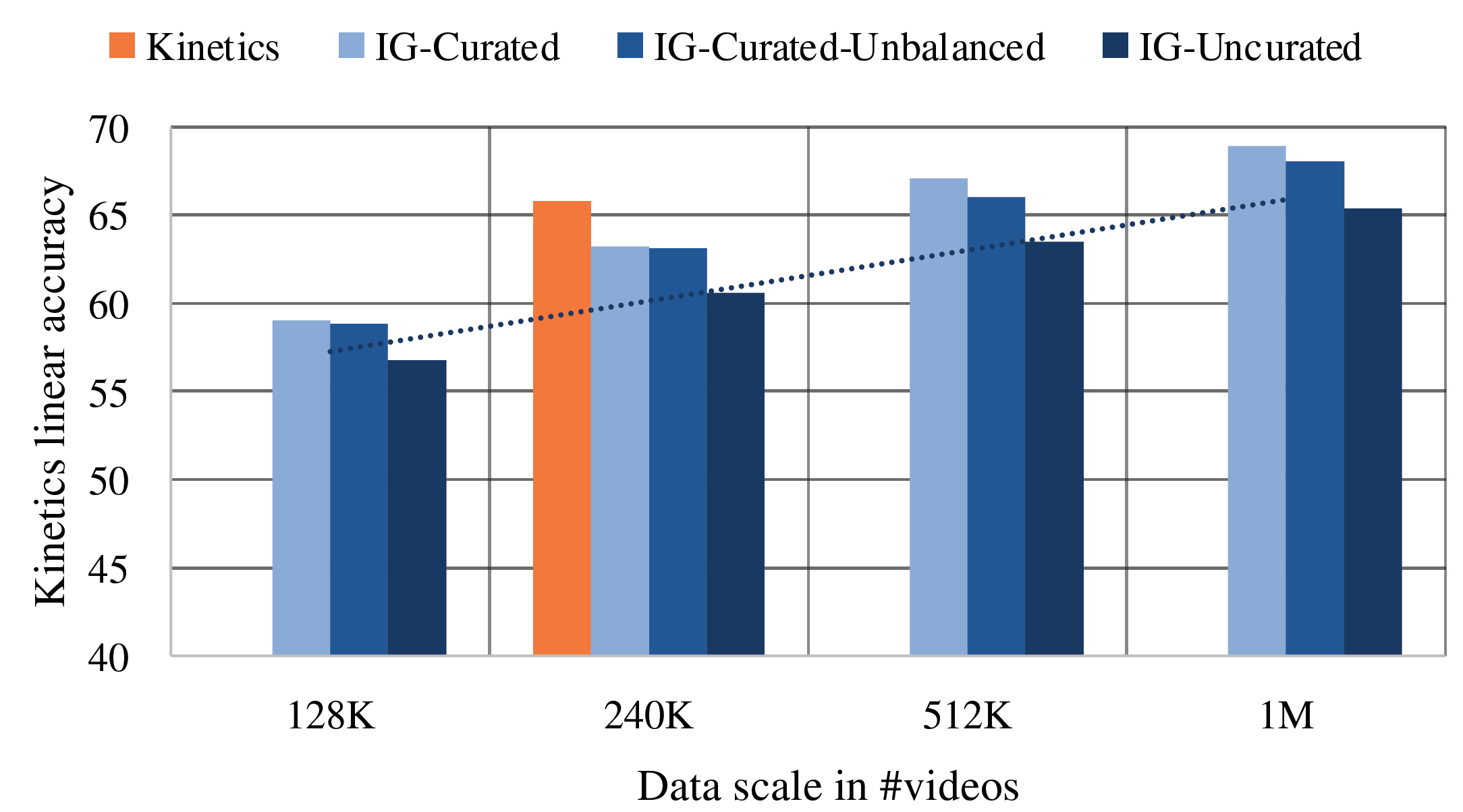
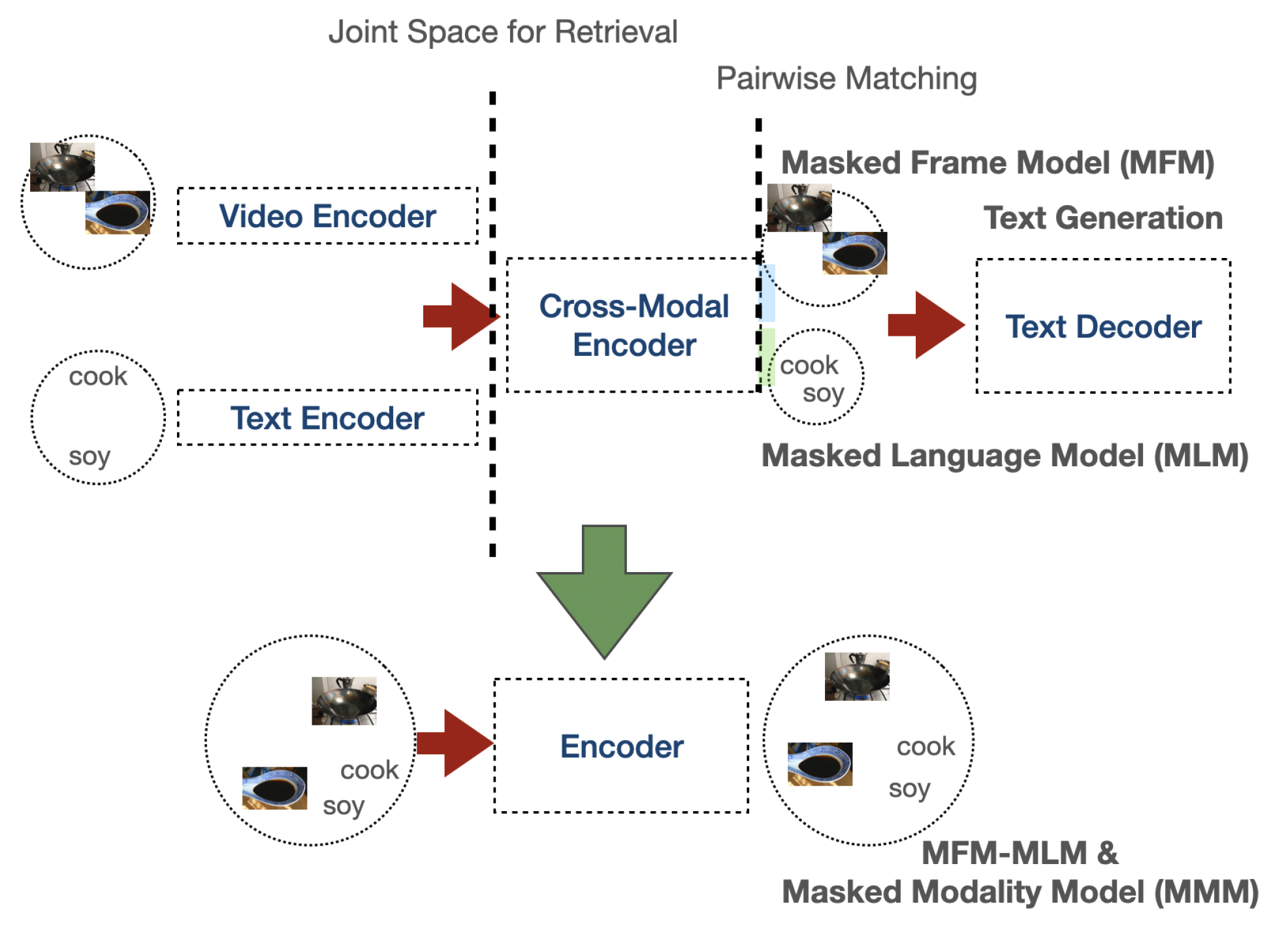
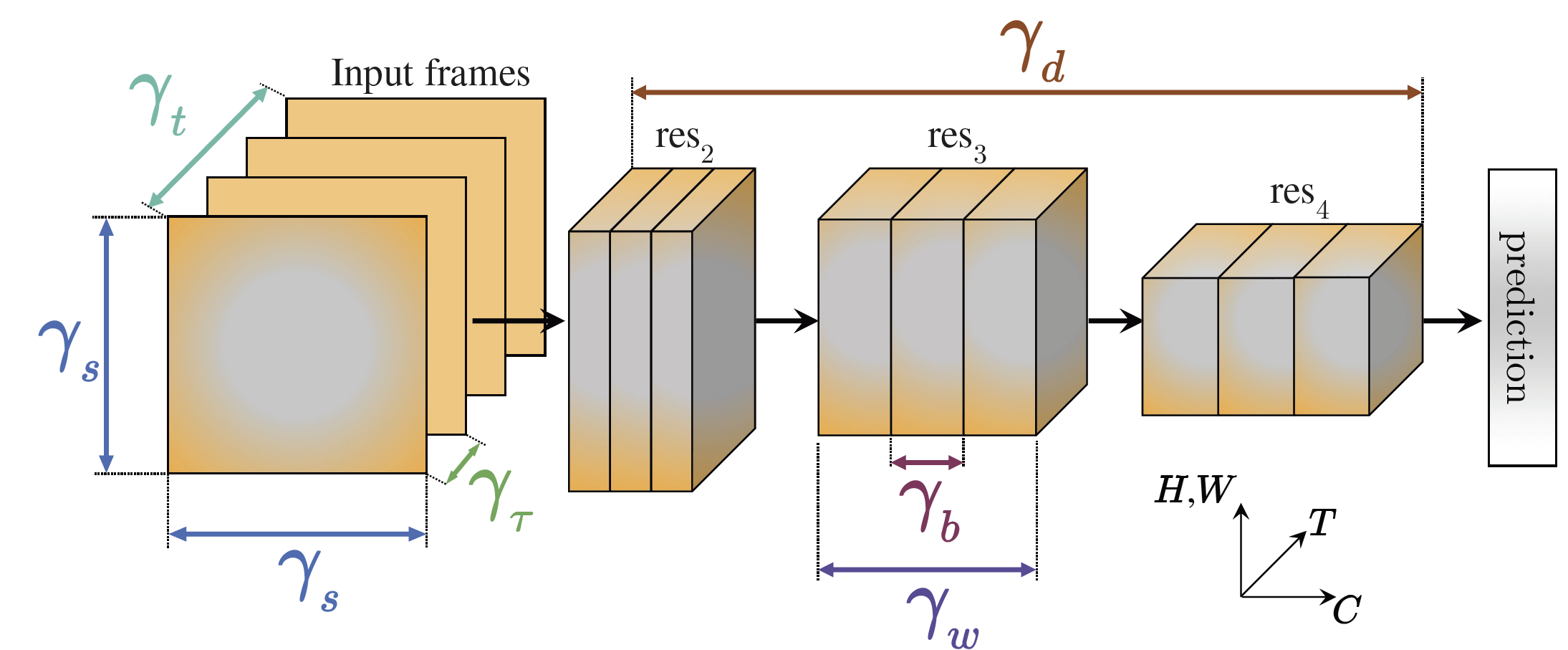
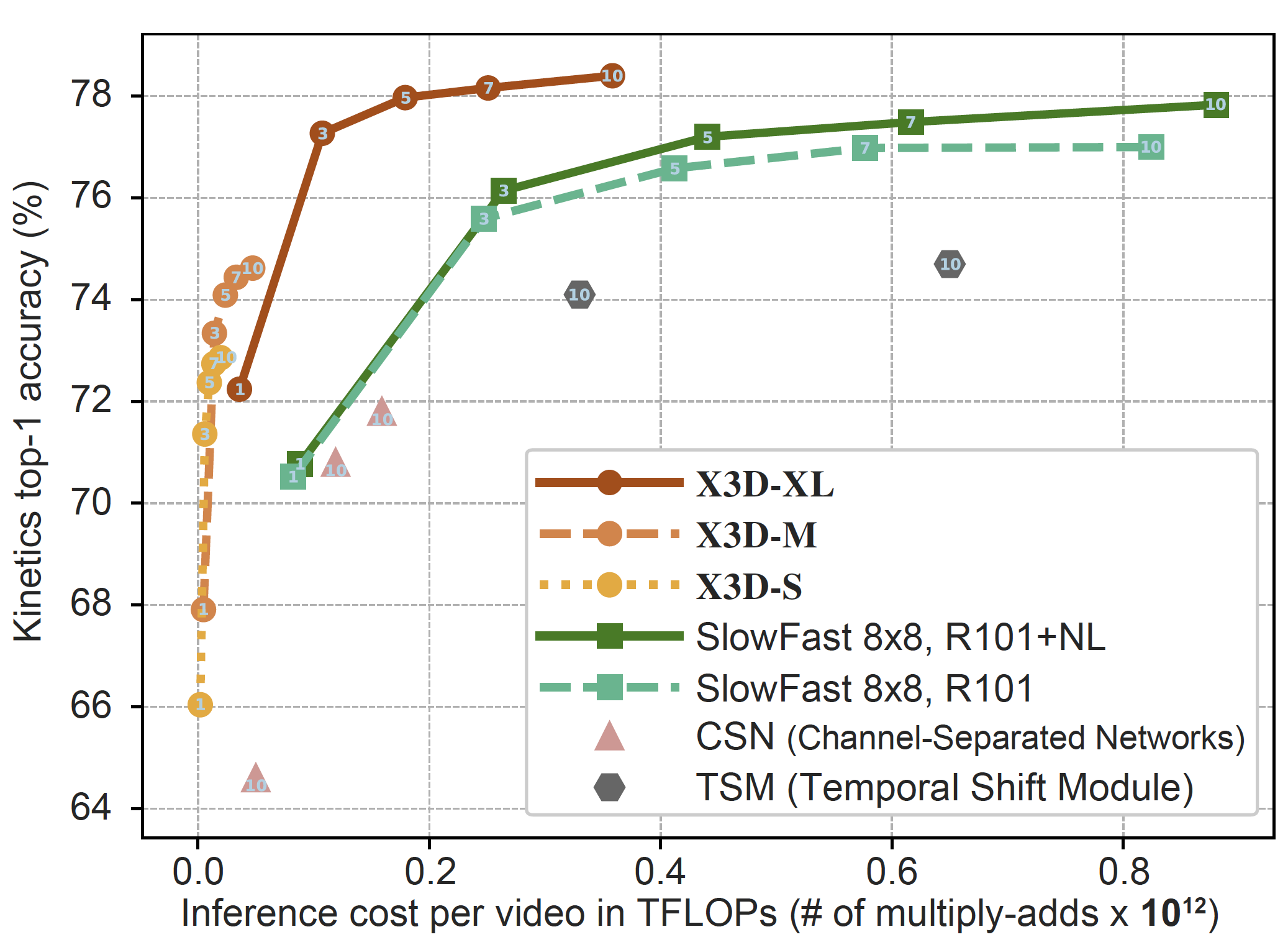
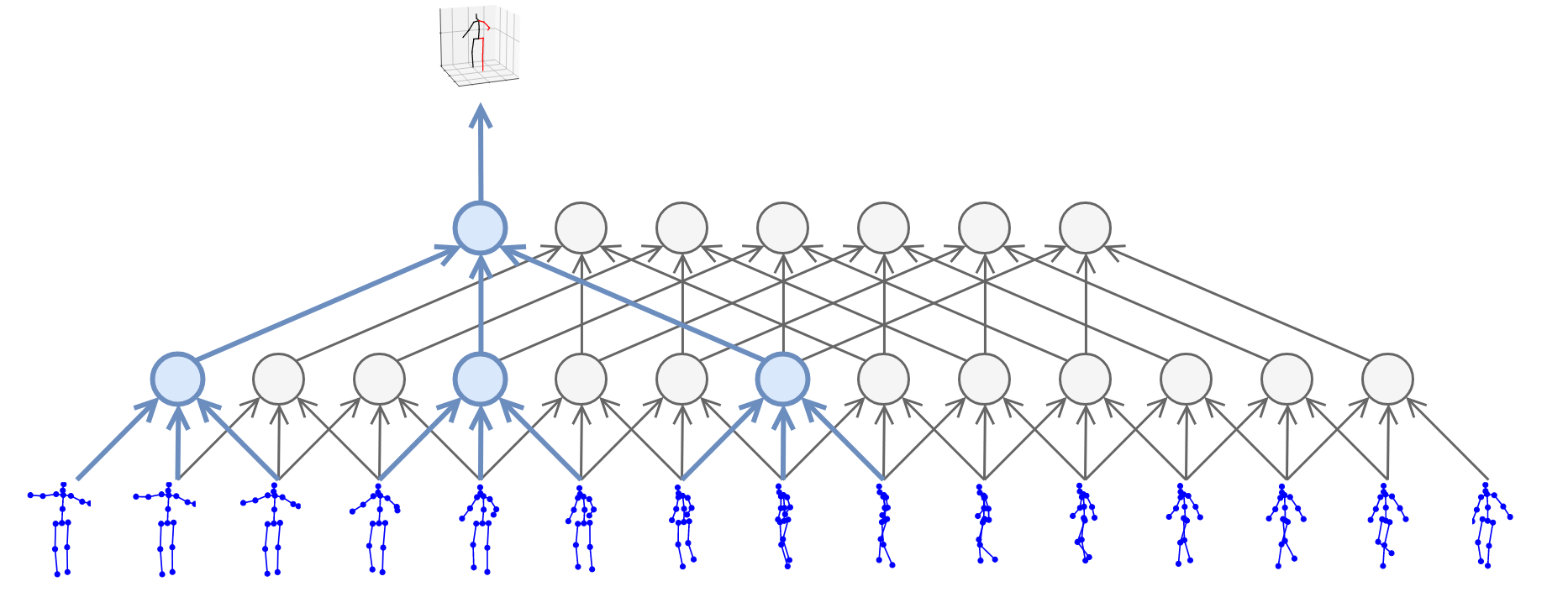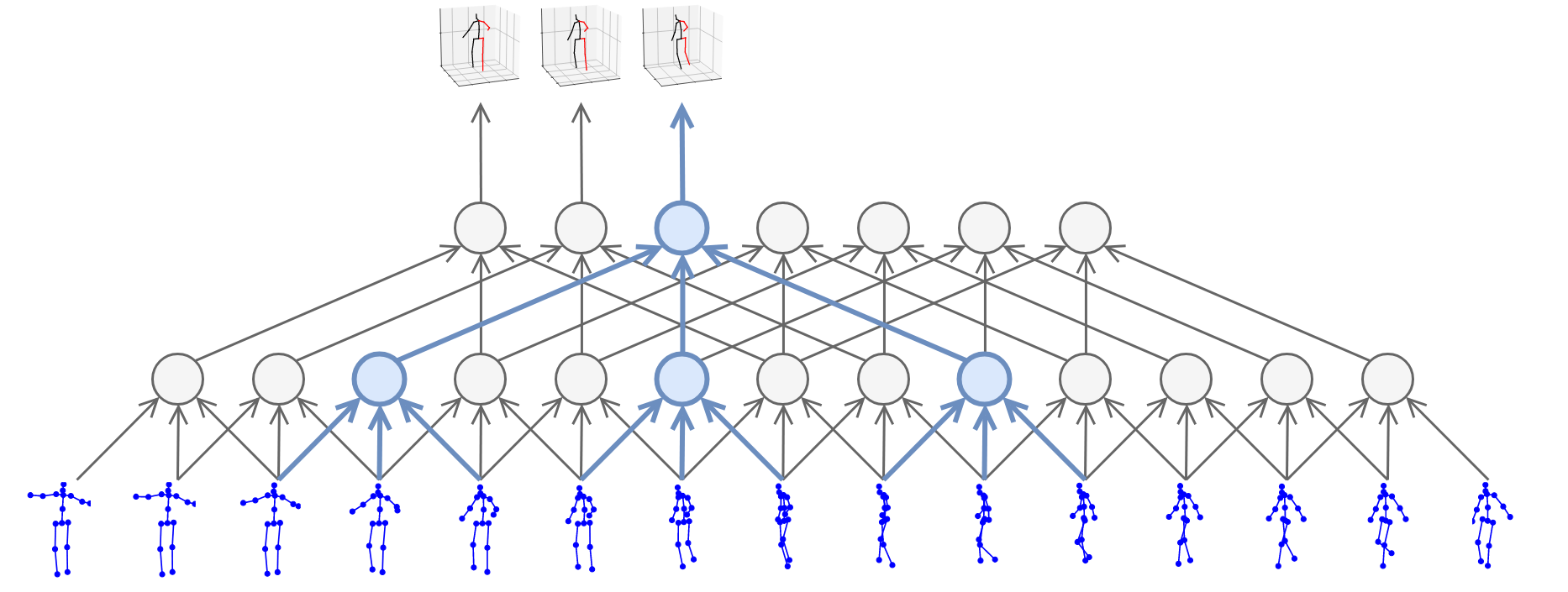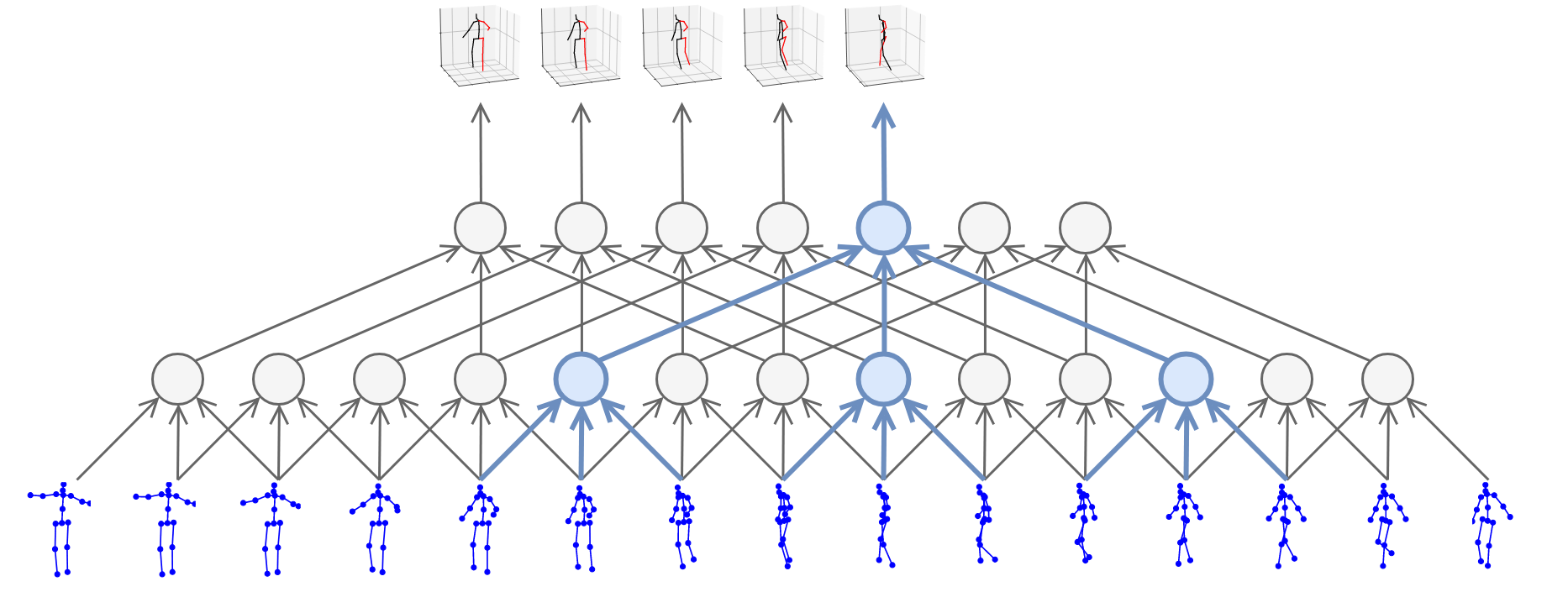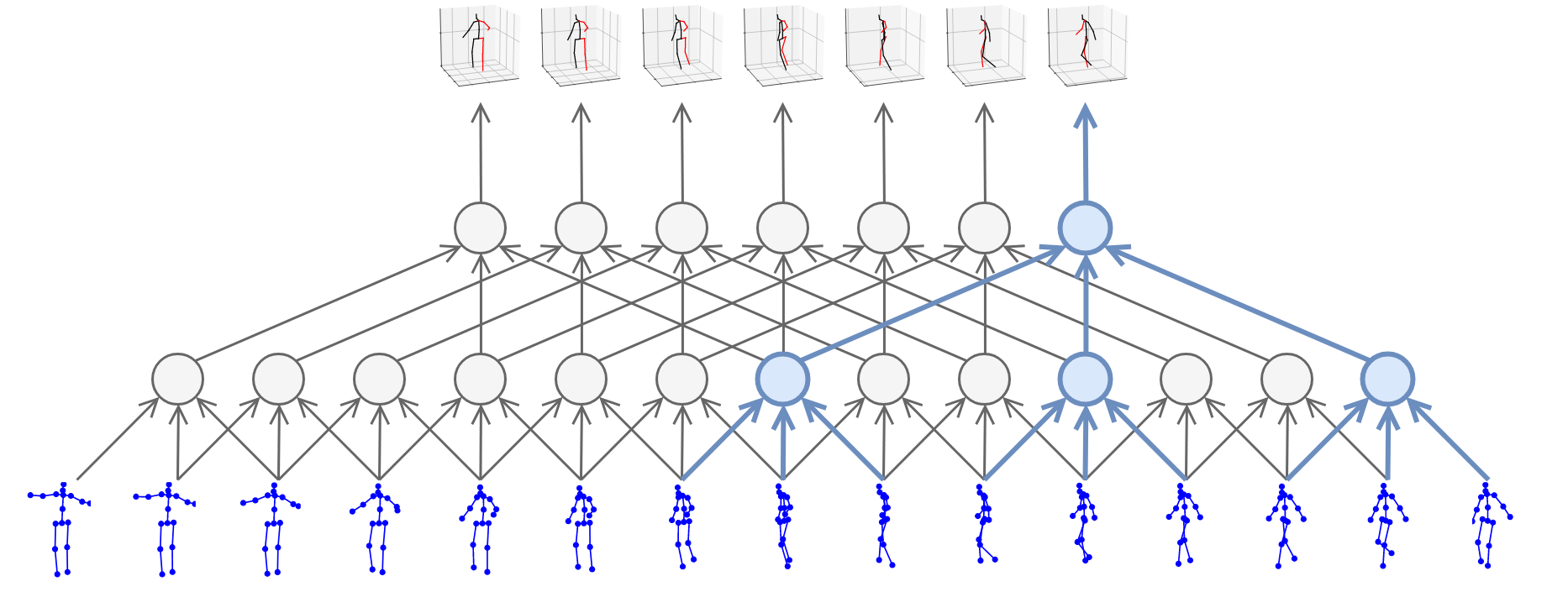
We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular,
efficient, and
reproducible components for a variety of video understanding tasks, including classification, detection,
self-supervised
learning, and low-level processing. The library covers a full stack of video understanding tools including
multimodal
data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further
supports
hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and
can be
used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision.